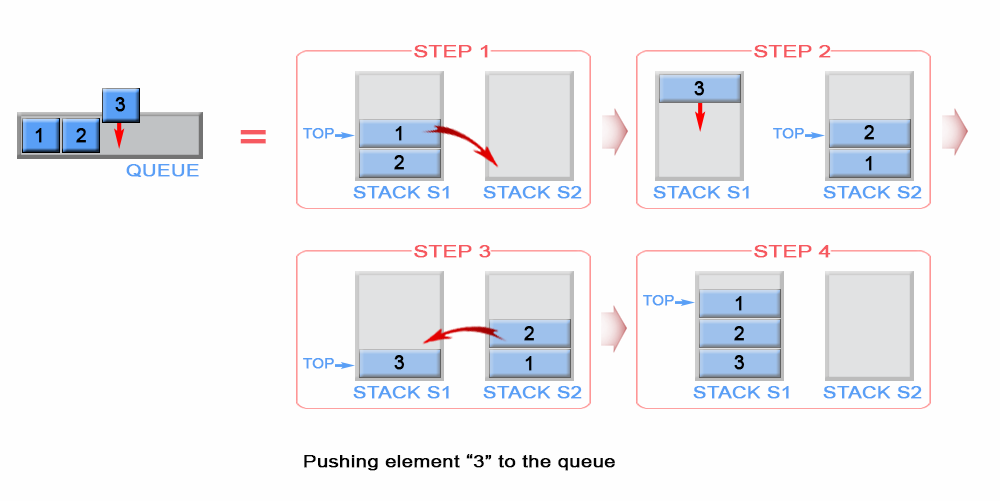
双指针
- LC-1 2数求和
先带上index排序 - LC-15 三数之和
排序,3指针: i,left=i+1, right=len(nums)-1;i/left/right都需要考虑去重 - LC-16 最接近的三数之和
同,排序,3指针 - LC-75 颜色分类
荷兰旗,head,mid=0,tail=n-1, mid=0交换mid和head前进, mid=2交换mid和tail,tail-1, 不然mid+1 - LC-11 盛最多水的容器
首尾指针,wide=j-i, height=min(h[i], h[j]), max(wide*height) - LC-763 划分字母区间
转成字典,key:字母,value:[start, end]的index,合并区间模板 - LC-80 删除排序数组中的重复项
重复k个的问题。核心:if i < k or nums[i] != nums[length - k],重新组织数组 - LC-581 最短无序连续子数组
分段左、中、右,找到左和右的边界
动态规划
- LC-300 最长上升子序列
i和j,初始化全长1,dp[i] = max(dp[i], dp[j]+1) if nums[i] > nums[j] - LC-1143 最长公共子序列
二维dp,初始化 n+1 和 m+1, 对角线更新 - LC-673 最长递增子序列的个数
LIS变种,维护一个count计数器, - LC-5 最长回文子串
二维dp,初始化全长,对角线单个字符,连续,左右缩进为true,更新最长length - LC-647 回文子串
二维dp,初始化全长,对角线单个字符,连续,左右缩进为true,累加 - LC-516 最长回文子序列
二维dp,后向遍历 - LC-221 最大正方形
二维dp,初始化+1全长,和上左对角比较 - LC-322 零钱兑换
dp,初始化全长+1正无穷,序列长度是金额数,取或不取 - LC-718 最长重复子数组
二维dp,初始化+1全长,dp[i][j] = dp[i-1][j-1] + 1 - LC-198 打劫家舍
dp,偷和不偷,初始化全长为对应数字 - LC-213 打劫家舍2
dp,环形问题,化解成2个一般的问题 - LC-62 不同路经
二维dp,初始化全长,贴边为1,上和左求和 - LC-63 不同路径2
二维dp,初始化全长,外围一圈有障碍及余下就为0 - LC-64 最小路经和
二维dp,初始化全长,贴边初始化 - LC-152 乘积最大子数组
乘积需要维护最大和最小值 - LC-523 连续的子数组和
前缀和 - LC-139 单词拆分
- LC-91 解码方法
- LC-264 丑数2
- LC-279 完全平方数
dp,初始化为全长该位置数字,dp为减去平方数加1 - LC-309 股票买卖
- LC-188 买卖股票最佳时机
- LC-343 整数拆分
- LC-416 分割等和子集
除以2,转化为01背包问题 - LC-42 接雨水
双指针 - LC-32 最长有效括号
使用堆,堆内放-1,左括号压入,右括号直接弹出 - LC-72 编辑距离
树
- LC-103 二叉树锯齿层次遍历
- LC-102 二叉树的层序遍历
- LC-107 二叉树层序遍历2
- LC-236 二叉树最近公共祖先
- LC-98 验证二叉搜索树
- LC-199 二叉树的右视图
- LC-101 对称二叉树
- LC-105 从前序与中序遍历序列构造二叉树
- LC-112 路径总和
- LC-113 路径总和2
- LC-124 二叉树中的最大路径和
- LC-129 根到叶子节点数字之和
- LC-958 二叉树完全性检验
- LC-104 二叉树最大深度
- LC-226 反转(对称)二叉树
- LC-114 二叉树展开成链表
- LC-230 二叉搜索树中第k小的树
- LC-662 二叉树最大宽度
- JZ-26 树的子结构
链表
- LC-206 反转链表
- LC-25 K个一组反转链表
- LC-92 反转链表2
- LC-21 合并2个有序链表
- LC-23 合并k个排序链表
- LC-141 环形链表
- LC-142 环形链表2
- LC-160 相交链表
- LC-19 删除链表倒数第N个元素
- LC-143 重排链表
找中点;反转链表;合并有序链表 - LC-234 回文链表
- LC-148 排序链表
- LC-82 删除排序链表中的重复元素
- LC-83 删除排序链表中的重复元素2
- LC-24 两两交换链表中的节点
- LC-328 奇偶链表
- LC-61 旋转链表
设定偶链表头,奇偶链表参考: odd.next = even.next; odd = odd.next - LC-86 分隔链表
- LC-382 链表随机节点
数学
- 高频-1 计算π
- LC-69 x 的平方根
- LC-2 两数相加
- LC-8 字符串转整数
- LC-50 Pow(x,n)
- JZ-16 数值的整数次方
递归,2个判断,正负幂,剩余n是否是2的倍数;进阶快速幂 - LC-400 第N个数字
- LC-43 字符串相乘
- LC-470 rand7() 实现 rand10()
- LC-264 丑数2
- LC-279 完全平方数
- LC-12 整数转罗马数字
计算中点
滑动窗口
(子串一般都是是滑动窗口法,子串求和使用前缀和)
- LC-523 连续的子数组和
- LC-3 无重复字符的最长子串
- LC-395 至少有k个重复字符子串
- LC-76 最小覆盖子串
- LC-239 滑动窗口最大值(栈)
- LC-209 长度最小的子数组
- LC-340 至多包含k个不同字符的最长子串
二分查找
- LC-33 搜索旋转排序数组
- LC-162 寻找峰值
- LC-240 搜索二维矩阵2
- LC-718 最长重复子数组
- LC-31 下一个排列
- LC-230 二叉搜索树中第k小的元素
- LC-34 排序数组中查找第一个和最后一个位置
- LC-287 寻找重复数
- LC-153 寻找旋转排序数组中的最小值(最大值)
回溯
DFS/BFS
字符串
- LC-151 反转字符串里的单词
- LC-165 比较版本号
- LC-93 复原IP地址
- LC-227 基本计算器2
使用单栈,注意数字 - LC-443 压缩字符串
- LC-394 字符串解码
- LC-207 课程表
- LC-71 简化路径
其他
双指针
LC-1 2数求和
双指针
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
Given nums = [2, 7, 11, 15], target = 9,
Because nums[0] + nums[1] = 2 + 7 = 9,
return [0, 1].
用一个dict来保存数据,key为数字,value为索引,代码如下:
class Solution: def twoSum(self, nums, target): """ :type nums: List[int] :type target: int :rtype: List[int] """ mem = dict() for index, item in enumerate(nums): if item in mem: return [mem[item], index] else: mem[target - item] = index双指针套路:
class Solution(object): def twoSum(self, nums, target): """ :type nums: List[int] :type target: int :rtype: List[int] """ sn = sorted((num, i) for i, num in enumerate(nums)) i, j = 0, len(nums) - 1 print(sn) while i < j: n, k = sn[i] m, l = sn[j] if n + m < target: i += 1 elif n + m > target: j -= 1 else: return [k, l]这里将原数组,转化为(value, index)一个tuple类型。对这个tuple类型进行了排序,这样既保留了原有的index和value,又排了顺序。然后就是常规的步骤了,两个指针各指向一头,如果大于target就移动右指针,反之移动左指针。最近发现很多问题都有涉及对这个tuple的运用,真的是一个很高阶的技能。
LC-15 3数求和
双指针
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有和为 0 且不重复的三元组。
注意:答案中不可以包含重复的三元组。
输入:nums = [-1,0,1,2,-1,-4]
输出:[[-1,-1,2],[-1,0,1]]
class Solution: def threeSum(self, nums: List[int]) -> List[List[int]]: ans = [] if len(nums) <=2: return ans # sort array nums.sort() for i in range(len(nums)): if nums[i] > 0: return ans left = i + 1 right = len(nums) - 1 if (i > 0 and nums[i] == nums[i-1]): # i 要考虑和前一个连续相同 continue while left < right: if nums[i] + nums[left] + nums[right] < 0: left += 1 elif nums[i] + nums[left] + nums[right] > 0: right -= 1 else: ans.append([nums[i], nums[left], nums[right]]) while left < right and nums[left] == nums[left+1]: left += 1 # left考虑和后一个连续相同 while right > left and nums[right] == nums[right-1]: right -= 1 # right 考虑和前一个连续相同 left += 1 right -= 1 return ans依然是双指针经典模板,if elif else 三段式;要避开连续所以要考虑和后一位的关系,多利用while来做连续判断。
LC-16 最接近的三数之和
给定一个包括 n 个整数的数组 nums 和 一个目标值 target。找出 nums 中的三个整数,使得它们的和与 target 最接近。返回这三个数的和。假定每组输入只存在唯一答案。
示例:
输入:nums = [-1,2,1,-4], target = 1
输出:2
解释:与 target 最接近的和是 2 (-1 + 2 + 1 = 2) 。
排序+双指针
class Solution: def threeSumClosest(self, nums: List[int], target: int) -> int: if len(nums) <=3: return sum(nums) n = len(nums) nums.sort() res = sum(nums[:3]) for i in range(n-2): left = i + 1 right = n - 1 while left < right: ans = nums[i] + nums[left] + nums[right] if ans > target: right -= 1 elif ans < target: left += 1 else: res = ans break if abs(ans-target) < abs(res-target): res = ans return resLC-75 颜色分类
给定一个包含红色、白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
此题中,我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
示例 1:
输入:nums = [2,0,2,1,1,0]
输出:[0,0,1,1,2,2]
遍历一遍
class Solution: def sortColors(self, nums: List[int]) -> None: """ Do not return anything, modify nums in-place instead. """ # 荷兰国旗问题 n = len(nums) start = 0 for i in range(0, n): if nums[i] == 0: nums[start], nums[i] = nums[i], nums[start] start += 1 for i in range(start, n): if nums[i] == 1: nums[start], nums[i] = nums[i], nums[start] start += 1荷兰国旗经典解法:
class Solution: def sortColors(self, nums: List[int]): """ Do not return anything, modify nums in-place instead. """ # 荷兰国旗问题 head = 0 tail = len(nums) - 1 mid = 0 while mid <= tail: if nums[mid] == 0: nums[head], nums[mid] = nums[mid], nums[head] head += 1 mid += 1 elif nums[mid] == 2: nums[mid], nums[tail] = nums[tail], nums[mid] tail -= 1 else: mid += 1LC-11 盛最多水的容器
给你 n 个非负整数 a1,a2,…,an,每个数代表坐标中的一个点 (i, ai) 。在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0) 。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
说明:你不能倾斜容器。
输入:[1,8,6,2,5,4,8,3,7]
输出:49
解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。
双指针,首尾指针代表面积
class Solution: def maxArea(self, height: List[int]) -> int: length = len(height) max_area = 0 i = 0 j = length - 1 while i < j: wide = j - i high = min(height[i], height[j]) area = high * wide if area > max_area: max_area = area if height[i] < height[j]: i += 1 else: j -= 1 return max_areaLC-763 划分字母区间
字符串 S 由小写字母组成。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。返回一个表示每个字符串片段的长度的列表。
示例:
输入:S = “ababcbacadefegdehijhklij”
输出:[9,7,8]
解释:
划分结果为 “ababcbaca”, “defegde”, “hijhklij”。
每个字母最多出现在一个片段中。
像 “ababcbacadefegde”, “hijhklij” 的划分是错误的,因为划分的片段数较少。
遍历一遍数组,建立字典,key为每个字母,value为首尾index,后将问题转化为合并区间问题。
合并区间模板:
# 动态维护merged = []intervals.sort()for interval in intervals: if not merged or interval[0] > merged[-1][1]: merged.append(interval) else: # 动态修改最后一个 end index merged[-1][1] = max(merged[-1][1], interval[1])class Solution: def partitionLabels(self, s: str) -> List[int]: dic = {} for i, v in enumerate(s): if v in dic.keys(): st = min(dic[v][0], i) ed = max(dic[v][1], i) dic[v] = [st, ed] else: dic[v] = [i, i] lt = list(dic.values()) # 排序是关键 lt.sort() # 合并区间模板 merged = [] for interval in lt: if not merged or interval[0] > merged[-1][1]: merged.append(interval) else: # 修改最后一个的第二位 merged[-1][1] = max(merged[-1][1], interval[1]) return [i[1] - i[0] + 1 for i in merged]LC-80 删除有序数组中的重复项 II
给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使每个元素 最多出现两次 ,返回删除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
示例 1:
输入:nums = [1,1,1,2,2,3]
输出:5, nums = [1,1,2,2,3]
解释:函数应返回新长度 length = 5, 并且原数组的前五个元素被修改为 1, 1, 2, 2, 3 。 不需要考虑数组中超出新长度后面的元素。
问题核心是只能采用原地模式,即不可以创造新的空间来保存数据。
对于有序数组,重复k个的问题。核心:if i < k or nums[i] != nums[length - k]
class Solution: def removeDuplicates(self, nums: List[int]) -> int: length = 0 for i in range(len(nums)): # 核心逻辑,排序数组和前n-k个元素比较,不重复保留,指针+1 if i < 2 or nums[i] != nums[length - 2]: nums[length] = nums[i] length += 1 return lengthLC-581 最短无序连续子数组
给你一个整数数组 nums ,你需要找出一个 连续子数组 ,如果对这个子数组进行升序排序,那么整个数组都会变为升序排序。
请你找出符合题意的 最短 子数组,并输出它的长度。
示例 1:
输入:nums = [2,6,4,8,10,9,15]
输出:5
解释:你只需要对 [6, 4, 8, 10, 9] 进行升序排序,那么整个表都会变为升序排序。
示例 2:
输入:nums = [1,2,3,4]
输出:0
class Solution(object): def findUnsortedSubarray(self, nums): """ :type nums: List[int] :rtype: int """ left = 0 right = 0 max = float('-inf') min = float('inf') for i in range(0, len(nums)): if nums[i] >= max: max = nums[i] else: right = i for i in range(len(nums) -1 , -1, -1): if nums[i] <= min: min = nums[i] else: left = i print(left, right) if left == right: return 0 else: return right - left + 1动态规划
LC-300 最长上升子序列
动态规划, 递归
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
输入:nums = [10,9,2,5,3,7,101,18]
输出:4
解释:最长递增子序列是 [2,3,7,101],因此长度为 4
转移方程:dp[i] = max{dp[i], dp[j]+1} if nums[i] > nums[j]
dp[i] 表示这一位上的最长子序列,对于[0, i-1]范围内所有的dp[j],都需要得到最大
class Solution: def lengthOfLIS(self, nums: List[int]) -> int: # 不连续 if len(nums) == 1: return 1 dp = [1] * len(nums) for i in range(len(nums)): for j in range(i): if nums[i] > nums[j]: dp[i] = max(dp[i], dp[j] + 1) return max(dp)LC-1143 最长公共子序列
动态规划, 递归
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
输入:text1 = “abcde”, text2 = “ace”
输出:3
解释:最长公共子序列是 “ace” ,它的长度为 3 。
看到2个字符串,要想到2维的dp问题
转移方程:dp[i][j] = dp[i-1][j-1] + 1, 当 text1[i-1] = text2[j-1]
dp[i][j] = max(dp[i-1][j], dp[i][j-1]), 当 text1[i-1] != text2[j-1]
状态初始化要考虑一个字符串是空串的可能性,
当 i = 0 时,dp[0][j] 表示的是 text1 中取空字符串 跟 text2的最长公共子序列,结果肯定为 0.
当 j = 0 时,dp[i][0] 表示的是 text2 中取空字符串 跟 text1的最长公共子序列,结果肯定为 0.
综上,当 i = 0 或者 j = 0 时,dp[i][j] 初始化为 0.
class Solution: def longestCommonSubsequence(self, text1: str, text2: str) -> int: dp = [[0] * (len(text2) + 1) for i in range(len(text1) + 1)] for i in range(1, len(text1) + 1): for j in range(1, len(text2) + 1): if text1[i-1] == text2[j-1]: dp[i][j] = dp[i-1][j-1] + 1 else: dp[i][j] = max(dp[i-1][j], dp[i][j-1]) return dp[-1][-1]LC-673 最长递增子序列的个数
动态规划, 递归
给定一个未排序的整数数组,找到最长递增子序列的个数。
输入: [1,3,5,4,7]
输出: 2
解释: 有两个最长递增子序列,分别是 [1, 3, 4, 7] 和[1, 3, 5, 7]。
LIS 问题,除了要知道最长递增子序列的长度以外,题目要知道有这个长度的子序列的数量。
dp[i]:到nums[i]为止的最长递增子序列长度
count[i]:到nums[i]为止的最长递增子序列个数
if 在nums[i] > nums[j] 分情况
if dp[j] + 1 > dp[i],说明最长递增子序列的长度增加了,dp[i] = dp[j] + 1,长度增加,数量不变 count[i] = count[j]
if dp[j] + 1 == dp[i],说明最长递增子序列的长度并没有增加,但是出现了长度一样的情况,数量增加 count[i] += count[j]
不断更新最大长度,最后返回所有dp[i] == maxlen 计数器的和
class Solution: def findNumberOfLIS(self, nums: List[int]): n = len(nums) if n == 1: return 1 dp = [1] * n count = [1] * n max_len = 0 for i in range(1, n): for j in range(i): if nums[i] > nums[j]: # 正常情况下,我们直接用 dp[i] = max(dp[1], dp[j]+1)就好 # 但是这里我们需要计数,所以拆成下面 if-else 的形式 if dp[j] + 1 > dp[i]: # 如果发现:当前长度 > 历史最佳长度 dp[i] = dp[j] + 1 # 更新dp[i], 这一步相当于 dp[i] = max(dp[1], dp[j]+1) count[i] = count[j] # 更新计数器,结果+1,但是计数是不变的 elif dp[j] + 1 == dp[i]: # 如果发现:当前长度=历史最佳长度 count[i] += count[j] # 更新计数器 max_len = max(max_len, dp[i]) #找到当前i的位置下,最长的子序列长度 # 在计数器里面查找最长子序列的总次数 res = 0 for i in range(n): if dp[i] == max_len: res += count[i] return resLC-5 最长回文子串
动态规划, 递归
给你一个字符串 s,找到 s 中最长的回文子串。
输入:s = “babad”
输出:“bab”
解释:“aba” 同样是符合题意的答案。
转移方程:if dp[i-1][j+1] == True and s[i] == s[j], then dp[i][j] = True
要求最长,则需要在循环的时候不断更新最长的长度,以及所对应的起始位置得到子串
注意:初始化矩阵为False的时候,需要把一些简单解先求出来。
class Solution: def longestPalindrome(self, s: str) -> str: maxlen = 0 start = 0 end = 0 if len(s) <= 1: return s dp = [[False] * len(s) for i in range(len(s))] # j start i end for i in range(0, len(s)): for j in range(0, i + 1): if i == j: dp[i][j] = True elif i - j == 1 and s[i] == s[j]: dp[i][j] = True elif dp[i-1][j+1] and s[i] == s[j]: dp[i][j] = True else: continue if i-j + 1 > maxlen: maxlen = i - j + 1 start = j end = i return s[start:end+1]LC-647 回文子串
动态规划, 递归
给定一个字符串,你的任务是计算这个字符串中有多少个回文子串。
输入:“abc”
输出:3
解释:三个回文子串: “a”, “b”, “c”
输入:“aaa”
输出:6
解释:6个回文子串: “a”, “a”, “a”, “aa”, “aa”, “aaa”
和LC5一样,区别在于,需要记录结果,且结果可以重复
class Solution: def countSubstrings(self, s: str) -> int: if len(s) <= 1: return 1 dp = [[False] * len(s) for i in range(len(s))] res = 0 for i in range(len(s)): for j in range(0, i+1): print(i,j) if i - j == 0: dp[i][j] = True res += 1 continue if i - j == 1 and s[i] == s[j]: dp[i][j] = True res += 1 continue if dp[i-1][j+1] and s[i] == s[j]: dp[i][j] = True res += 1 continue return resLC-516 最长回文子序列
动态规划, 递归
给你一个字符串 s ,找出其中最长的回文子序列,并返回该序列的长度。
子序列定义为:不改变剩余字符顺序的情况下,删除某些字符或者不删除任何字符形成的一个序列。
输入:s = “bbbab”
输出:4
解释:一个可能的最长回文子序列为 “bbbb” 。
转移方程:if s[i] == s[j] then dp[i][j] = dp[i+1][j-1] + 2
if s[i] != s[j] then dp[i][j] = max(dp[i+1][j], dp[i][j-1])
class Solution: def longestPalindromeSubseq(self, s: str) -> int: if len(s) <= 1: return 1 dp = [[0] * len(s) for i in range(len(s))] for i in range(len(s)): dp[i][i] = 1 # i 是首,j 是尾,循环时i变小,j变大, for i in range(len(s) - 1, -1, -1): for j in range(i+1, len(s), 1): if s[i] == s[j]: dp[i][j] = dp[i+1][j-1] + 2 else: dp[i][j] = max(dp[i+1][j], dp[i][j-1]) return dp[0][-1] LC-221 最大正方形
动态规划, 递归
在一个由 ‘0’ 和 ‘1’ 组成的二维矩阵内,找到只包含 ‘1’ 的最大正方形,并返回其面积。
输入:matrix = [
[“1”,“0”,“1”,“0”,“0”],
[“1”,“0”,“1”,“1”,“1”],
[“1”,“1”,“1”,“1”,“1”],
[“1”,“0”,“0”,“1”,“0”]
]
输出:4
dp数组中保存每个位置对应的最大正方形的边长
转移方程:dp[i][j] = min(dp[i-1][j], dp[i][j-1], dp[i-1][j-1]) + 1
class Solution: def maximalSquare(self, matrix: List[List[str]]) -> int: m, n = len(matrix), len(matrix[0]) dp = [[0] * (n + 1) for _ in range(m + 1)] for i in range(m + 1): dp[i][0] = 0 for j in range(n + 1): dp[0][j] = 0 for i in range(1, m + 1): for j in range(1, n + 1): if matrix[i-1][j-1] == '1': dp[i][j] = min(dp[i-1][j], dp[i][j-1], dp[i-1][j-1]) + 1 else: dp[i][j] = 0 return max([max(i) for i in dp]) ** 2LC-322 零钱兑换
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。
输入:coins = [1, 2, 5], amount = 11
输出:3
解释:11 = 5 + 5 + 1
dp存储各个金额
转移方程:dp[i] = min(dp[i], dp[i - coin] + 1)
class Solution: def coinChange(self, coins: List[int], amount: int): dp = [float('inf')] * (amount + 1) # dp 存储的是总金额 这个要想到 dp[0] = 0 for i in range(amount + 1): for coin in coins: # 只有当硬币面额不大于要求面额数时,才能取该硬币 if coin <= i: dp[i] = min(dp[i], dp[i - coin] + 1) if dp[amount] <= amount: return dp[amount] else: return -1LC-718 最长重复子数组
给两个整数数组 A 和 B ,返回两个数组中公共的、长度最长的子数组的长度。
示例:
输入:
A: [1,2,3,2,1]
B: [3,2,1,4,7]
输出:3
解释:
长度最长的公共子数组是 [3, 2, 1] 。
转移方程:dp[i][j] = dp[i-1][j-1] + 1
class Solution: def findLength(self, nums1: List[int], nums2: List[int]) -> int: if not nums1 or not nums2: return 0 a, b = len(nums1), len(nums2) dp = [[0] * (a + 1) for _ in range(b + 1)] for i in range(1, b+1): for j in range(1, a+1): if nums1[j - 1] == nums2[i - 1]: dp[i][j] = dp[i-1][j-1] + 1 # 子串需要严格相等 # else: # dp[i][j] = dp[i-1][j-1] return max([max(dp[i][:]) for i in range(len(dp))])LC-198 打劫家舍
动态规划, 递归
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
输入:[1,2,3,1]
输出:4
转移方程:dp[i] = max(nums[i] + dp[i-2], dp[i-1])
class Solution: def rob(self, nums: List[int]) -> int: if len(nums) <= 1: return nums[0] dp = [i for i in range(len(nums))] dp[0] = nums[0] dp[1] = max(nums[1], nums[0]) # dp[1] 取 1 和 2 中的 max for i in range(2, len(nums)): dp[i] = max(nums[i]+dp[i-2], dp[i-1]) return dp[-1]LC-213 打劫家舍2
动态规划, 递归
你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都 围成一圈 ,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警 。
给定一个代表每个房屋存放金额的非负整数数组,计算你 在不触动警报装置的情况下 ,今晚能够偷窃到的最高金额。
输入:nums = [1,2,3,1]
输出:4
解释:你可以先偷窃 1 号房屋(金额 = 1),然后偷窃 3 号房屋(金额 = 3)。
偷窃到的最高金额 = 1 + 3 = 4 。
转移方程:dp[i] = max(dp[i-2] + nums[i], dp[i-1])
class Solution: def rob(self, nums: List[int]) -> int: def sub_rob(nums,n) : dp = [0] * n dp[0] = nums[0] dp[1] = max(nums[0],nums[1]) for i in range(2,n): dp[i] = max(dp[i-2] + nums[i], dp[i-1]) return dp[-1] n = len(nums) if n <3: return max(nums) nums1 = nums[1:] nums2 = nums[:-1] result1 = sub_rob(nums1,n-1) result2 = sub_rob(nums2,n-1) return max(result1,result2)LC-62 不同路径
动态规划, 递归
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
输入:m = 3, n = 2
输出:3
解释:
从左上角开始,总共有 3 条路径可以到达右下角。
- 向右 -> 向下 -> 向下
- 向下 -> 向下 -> 向右
- 向下 -> 向右 -> 向下
转移方程: dp[i][j] = dp[i-1][j] + dp[i][j-1]
class Solution: def uniquePaths(self, m: int, n: int): if m <=0 or n <= 0: return 0 dp = [[0] * n for _ in range(m)] # 外侧一圈要先初始化为1 for i in range(m): dp[i][0] = 1 for j in range(n): dp[0][j] = 1 for i in range(1, m): for j in range(1, n): dp[i][j] = dp[i-1][j] + dp[i][j-1] return dp[-1][-1]LC-63 不同路径2
动态规划, 递归
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
输入:obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]]
输出:2
解释:
3x3 网格的正中间有一个障碍物。
从左上角到右下角一共有 2 条不同的路径:
- 向右 -> 向右 -> 向下 -> 向下
- 向下 -> 向下 -> 向右 -> 向右
转移方程: dp[i][j] = dp[i-1][j] + dp[i][j-1]
if 有障碍物 then dp[i][j] = 0, 注意外圈有障碍物,则余下都为0,需要额外处理
class Solution: def uniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int: if not obstacleGrid: return 0 m = len(obstacleGrid) n = len(obstacleGrid[0]) dp = [[0] * n for _ in range(m)] # 外侧一圈要先初始化为1 for i in range(m): if obstacleGrid[i][0] == 1: for x in range(i, m): dp[x][0] = 0 break else: dp[i][0] = 1 for j in range(n): if obstacleGrid[0][j] == 1: for x in range(j, n): dp[0][x] = 0 break else: dp[0][j] = 1 for i in range(1, m): for j in range(1, n): if obstacleGrid[i][j] == 1: dp[i][j] = 0 else: dp[i][j] = dp[i-1][j] + dp[i][j-1] return dp[-1][-1]LC-64 最小路径和
动态规划, 递归
给定一个包含非负整数的 m x n 网格 grid ,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
说明:每次只能向下或者向右移动一步。
输入:grid = [[1,3,1],[1,5,1],[4,2,1]]
输出:7
解释:因为路径 1→3→1→1→1 的总和最小。
转移方程:dp[i][j] = min(dp[i-1][j], dp[i][j-1]) + grid[i][j]
注意贴边的一圈都只能从左到右,或者从上到下得到值
class Solution: def minPathSum(self, grid: List[List[int]]) -> int: if not grid: return 0 m = len(grid) n = len(grid[0]) dp = [[0] * (n) for _ in range(m)] dp[0][0] = grid[0][0] for i in range(1, n): dp[0][i] = dp[0][i-1] + grid[0][i] for j in range(1, m): dp[j][0] = dp[j-1][0] + grid[j][0] for i in range(1, m): for j in range(1, n): dp[i][j] = min(dp[i-1][j], dp[i][j-1]) + grid[i][j] return dp[-1][-1]LC-152 乘积最大子数组
给你一个整数数组 nums ,请你找出数组中乘积最大的连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。
示例 1:
输入: [2,3,-2,4]
输出: 6
解释: 子数组 [2,3] 有最大乘积 6。
转移方程:max_v = max(max_a * nums[i], nums[i], min_a * nums[i])
min_v = min(min_a * nums[i], nums[i], max_a * nums[i])
乘积最大可能是负数乘负数,或者正数乘正数,所以需要维护2个队列
class Solution: def maxProduct(self, nums: List[int]) -> int: # 乘积需要维护2个值,最大值和最小值 if len(nums) == 1: return nums[0] max_a = nums[0] min_a = nums[0] res = nums[0] for i in range(1, len(nums)): max_v = max(max_a * nums[i], nums[i], min_a * nums[i]) min_v = min(min_a * nums[i], nums[i], max_a * nums[i]) res = max(max_v, res) max_a = max_v min_a = min_v return resLC-523 连续的子数组和
前缀和
给你一个整数数组 nums 和一个整数 k ,编写一个函数来判断该数组是否含有同时满足下述条件的连续子数组
子数组大小 至少为 2 ,且
子数组元素总和为 k 的倍数。
如果存在,返回 true ;否则,返回 false 。
如果存在一个整数 n ,令整数 x 符合 x = n * k ,则称 x 是 k 的一个倍数。0 始终视为 k 的一个倍数。
示例 1:
输入:nums = [23,2,4,6,7], k = 6
输出:true
解释:[2,4] 是一个大小为 2 的子数组,并且和为 6 。
看到子数组和求和问题的时候,要想到前缀和方法
class Solution: def checkSubarraySum(self, nums: List[int], k: int) -> bool: # 前缀和+哈希表,查看是否有连续的一段元素的,和为k的倍数就行,同余定理,i%m - j%m = (i-j)%m n = len(nums) if n < 2: return False # 记录前缀和,除以k的余数 sub = [0] * (1 + len(nums)) for i in range(len(nums)): sub[i+1] = (sub[i] + nums[i]) % k # 记录相同前缀和对k取余,记录所有余数相同的位置list dic = {} for idx, pre in enumerate(sub): print(pre) if pre not in dic.keys(): dic[pre] = [idx] else: dic[pre].append(idx) # 查找是否存在一段, max - min >= 2 来判断 for k, v in dic.items(): if max(v) - min(v) >=2: return True return FalseLC-139 单词拆分
给定一个非空字符串 s 和一个包含非空单词的列表 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。
说明:
拆分时可以重复使用字典中的单词。
你可以假设字典中没有重复的单词。
示例 1:
输入: s = “leetcode”, wordDict = [“leet”, “code”]
输出: true
解释: 返回 true 因为 “leetcode” 可以被拆分成 “leet code”。
转移方程:dp[j] = dp[i] and s[i:j]
class Solution: def wordBreak(self, s: str, wordDict: List[str]) -> bool: n = len(s) dp = [False] * (n + 1) dp[0] = True for i in range(n): for j in range(i+1, n+1): if dp[i] and s[i:j] in wordDict: dp[j] = True return dp[-1]LC-91 解码方法
要解码 已编码的消息,所有数字必须基于上述映射的方法,反向映射回字母(可能有多种方法)。例如,“11106” 可以映射为:
“AAJF” ,将消息分组为 (1 1 10 6)
“KJF” ,将消息分组为 (11 10 6)
输入:s = “12”
输出:2
解释:它可以解码为 “AB”(1 2)或者 “L”(12)。
递推公式:
$$
\left{\begin{array}{l}
f[i]=f[i-1], 1 \leqslant a \leq 9 \newline
f[i]=f[i-2], 10 \leqslant b \leqslant 26 \newline
f[i]=f[i-1]+f[i-2], 1 \leqslant a \leq 9,10 \leqslant b \leqslant 26
\end{array}\right.
$$
class Solution: def numDecodings(self, s: str) -> int: length = len(s) dp = [0] * (length + 1) dp[0] = 1 if 1 <= int(s[0]) <= 9: dp[1] = 1 # 注意一位和两位的条件 for i in range(1, length): if 1 <= int(s[i]) <= 9: dp[i + 1] += dp[i] if 10 <= int(s[i - 1:i + 1]) <= 26: dp[i + 1] += dp[i - 1] return dp[-1]LC-264 丑数2
给你一个整数 n ,请你找出并返回第 n 个 丑数 。
丑数 就是只包含质因数 2、3 和/或 5 的正整数。
示例 1:
输入:n = 10
输出:12
解释:[1, 2, 3, 4, 5, 6, 8, 9, 10, 12] 是由前 10 个丑数组成的序列。
方法一,利用堆排序,根据丑数定义,对前一个数以此乘以 [2, 3, 5],不断加入到堆中。一头入堆,一头出堆,直到等于n结束。
class Solution: def nthUglyNumber(self, n: int) -> int: hq = [] heapq.heappush(hq, 1) used = set() used.add(1) ugly_factors = [2, 3, 5] for i in range(n): print(i) x = heapq.heappop(hq) if i == n-1: return x for u in ugly_factors: if x * u not in used: used.add(x * u) heapq.heappush(hq, x * u) return -1方法二,动态规划三指针,三个指针起始指向 index = 0,更新时将3个指针分别乘以对应的 2,3,5;最小的值更新为下一个index,被选中的指针+1
转移方程:dp[i] = min(dp[p2] * 2, dp[p3] * 3, dp[p5] * 5)
class Solution: def nthUglyNumber(self, n: int) -> int: dp = [1] * n p2, p3, p5 = 0, 0, 0 for i in range(1, n, 1): p2_num, p3_num, p5_num = dp[p2] * 2, dp[p3] * 3, dp[p5] * 5 min_num = min(p2_num, p3_num, p5_num) dp[i] = min_num if min_num == p2_num: p2 += 1 if min_num == p3_num: p3 += 1 if min_num == p5_num: p5 += 1 return dp[-1]LC-279 完全平方数
给定正整数 n,找到若干个完全平方数(比如 1, 4, 9, 16, …)使得它们的和等于 n。你需要让组成和的完全平方数的个数最少。
给你一个整数 n ,返回和为 n 的完全平方数的 最少数量 。
示例 1:
输入:n = 12
输出:3
解释:12 = 4 + 4 + 4
示例 2:
输入:n = 13
输出:2
解释:13 = 4 + 9
转移方程: dp[num] = min(dp[num], dp[num - i * i] + 1)
class Solution: def numSquares(self, n: int) -> int: dp = [1] * (n + 1) dp[0] = 0 for num in range(1, n + 1): dp[num] = num tmp = [] for i in range(1, int(num ** 0.5) + 1): tmp.append(dp[num - i**2] + 1) dp[num] = min(tmp) return dp[-1]LC-309 最佳买卖股票时机含冷冻期
给定一个整数数组,其中第 i 个元素代表了第 i 天的股票价格 。
设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票):
你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
卖出股票后,你无法在第二天买入股票 (即冷冻期为 1 天)。
示例:
输入: [1,2,3,0,2]
输出: 3
解释: 对应的交易状态为: [买入, 卖出, 冷冻期, 买入, 卖出]
股票类题目运用状态机,设定3个维度:1. 天数、2. 次数、3. 状态(持有、不持有、不持有冷冻),此题没有次数,只需要构建2维数组
转移方程:
# 持有dp[i][0] = max(dp[i-1][0], dp[i-1][2] - prices[i])# 不持有,不冷冻dp[i][1] = max(dp[i-1][1], dp[i-1][0] + prices[i])# 不持有,冷冻dp[i][2] = max(dp[i-1][1], dp[i-1][2])class Solution: def maxProfit(self, prices: List[int]) -> int: if len(prices) <= 1: return 0 # 天数、次数、状态:持有 不持有 冷冻 dp = [[0 for j in range(3)] for _ in range(len(prices))] dp[0][0] = -prices[0] for i in range(1, len(prices)): for j in range(3): # 持有 dp[i][0] = max(dp[i-1][0], dp[i-1][2] - prices[i]) # 不持有 不冷冻 dp[i][1] = max(dp[i-1][1], dp[i-1][0] + prices[i]) # 不持有 冷冻 dp[i][2] = max(dp[i-1][1], dp[i-1][2]) return max(dp[-1][1], dp[-1][2])LC-188 买卖股票的最佳时机 IV
给定一个整数数组 prices ,它的第 i 个元素 prices[i] 是一支给定的股票在第 i 天的价格。设计一个算法来计算你所能获取的最大利润。你最多可以完成 k 笔交易。注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入:k = 2, prices = [2,4,1]
输出:2
解释:在第 1 天 (股票价格 = 2) 的时候买入,在第 2 天 (股票价格 = 4) 的时候卖出,这笔交易所能获得利润 = 4 - 2 = 2。
重点:
- 第 1 天就买入需要进行初始化 - prices[0]
- 交易成功 1 次需要更新 k
转移方程:
dp[i][0][k]=max(dp[i−1][0][k],dp[i−1][1][k]+prices[i])
dp[i][1][k]=max(dp[i−1][1][k],dp[i−1][0][k−1]−prices[i])
class Solution: def maxProfit(self, k: int, prices: List[int]) -> int: if len(prices) <= 1 or k <= 0: return 0 dp = [[[i for i in range(2)] for j in range(k+1)] for n in range(len(prices))] # 补第一天就买入的case, k=0,交易不会成功 for i in range(1, k+1): dp[0][i][1] = -prices[0] for i in range(1, len(prices)): for j in range(1, k+1): dp[i][j][0] = max(dp[i-1][j][0], dp[i-1][j][1] + prices[i]) dp[i][j][1] = max(dp[i-1][j][1], dp[i-1][j-1][0] - prices[i]) return max([j[0] for i in dp for j in i])LC-343 整数拆分
给定一个正整数 n,将其拆分为至少两个正整数的和,并使这些整数的乘积最大化。 返回你可以获得的最大乘积。
示例 1:
输入: 2
输出: 1
解释: 2 = 1 + 1, 1 × 1 = 1。
示例 2:
输入: 10
输出: 36
解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36。
转移函数:
class Solution: def integerBreak(self, n: int) -> int: dp = [0] * (n + 1) dp[0] = 1 dp[1] = 1 for i in range(2, n + 1): for j in range(i): dp[i] = max(dp[i], j * (i-j), j * dp[i-j]) return dp[-1]LC-416 分割等和子集
给你一个 只包含正整数 的 非空 数组 nums。
请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
示例 1:
输入:nums = [1,5,11,5]
输出:true
解释:数组可以分割成 [1, 5, 5] 和 [11] 。
动态规划,01 背包问题
转移方程:
dp[i][j] = dp[i-1][j] or dp[i-1][j - nums[i]]
class Solution: def canPartition(self, nums: List[int]) -> bool: sum_num = sum(nums) if sum_num % 2 == 1: return False target = sum_num // 2 dp = [[False] * (target + 1) for i in range(len(nums))] for i in range(len(nums)): dp[i][0] = True for i in range(len(nums)): for j in range(1, target + 1): if nums[i] == j: dp[i][j] = True if nums[i] < j: dp[i][j] = dp[i-1][j] or dp[i-1][j - nums[i]] # 比目标值大,直接拿上一位 if nums[i] > j: dp[i][j] = dp[i-1][j] # print(dp) return dp[-1][-1]LC-42 接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
输出:6
解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
关键方程:res += min(l_max[i], r_max[i]) - height[i]
class Solution: def trap(self, height: List[int]): # 核心思想: res += min(l_max[i], r_max[i]) - height[i]; if not height: return 0 left_p = 0 right_p = len(height) - 1 left_max = 0 right_max = 0 res = 0 while left_p <= right_p: left_max = max(left_max, height[left_p]) right_max = max(right_max, height[right_p]) if left_max < right_max: res += left_max - height[left_p] left_p += 1 else: res += right_max - height[right_p] right_p -= 1 return res也可以用dp来解,转移方程left_max[i] = max(height[i], left_max[i-1])
right_max[i] = max(height[i], right_max[i + 1])
class Solution: def trap(self, height: List[int]) -> int: # 核心思想: res += min(l_max[i], r_max[i]) - height[i]; if not height: return 0 left_max = [height[0]] + [0] * (len(height) - 1) right_max = [0] * (len(height) - 1) + [height[-1]] for i in range(1, len(height)): left_max[i] = max(height[i], left_max[i-1]) for i in range(len(height) - 2, -1 , -1): right_max[i] = max(height[i], right_max[i + 1]) res = 0 for j in range(len(height)): ans = min(left_max[j], right_max[j]) - height[j] res += ans return resLC-32 最长有效括号
给你一个只包含 ‘(’ 和 ‘)’ 的字符串,找出最长有效(格式正确且连续)括号子串的长度。
输入:s = “)()())”
输出:4
解释:最长有效括号子串是 “()()”
用堆来保存括号的index
class Solution: def longestValidParentheses(self, s: str) -> int: stack = [-1] res = 0 for i, j in enumerate(s): if j == "(": stack.append(i) else: stack.pop() if stack: # stack 不为空正常计算max res = max(res, i - stack[-1]) else: # stac 为空则直接把右括号index压入 stack.append(i) return resultLC-72 编辑距离
给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
插入一个字符
删除一个字符
替换一个字符
示例1:
输入:word1 = “horse”, word2 = “ros”
输出:3
解释:
horse -> rorse (将 ‘h’ 替换为 ‘r’)
rorse -> rose (删除 ‘r’)
rose -> ros (删除 ‘e’)
转移方程:if word1[i] == word2[j] then dp[i][j] = min(dp[i-1][j] + 1, dp[i][j-1] + 1, dp[i-1][j-1])
else dp[i][j] = min(dp[i-1][j] + 1, dp[i][j-1] + 1, dp[i-1][j-1] + 1)
初始化第一行和第一列,想到二维矩阵,dp[i][j]由dp[i-1][j-1]表示替换操作,dp[i][j]由dp[i-1][j]表示删除操作+1,dp[i][j]由dp[i][j-1]表示插入操作+1
dp[i][0] 和 dp[0][j] 初始化为对应单词和空字符串之间的编辑距离。
class Solution: def minDistance(self, word1: str, word2: str) -> int: if len(word1) == 0: return len(word2) if len(word2) == 0: return len(word1) dp = [[0] * (len(word1) + 1) for _ in range(len(word2) + 1)] for i in range(1, len(dp)): dp[i][0] = i for j in range(1, len(dp[0])): dp[0][j] = j for i in range(1, len(dp)): for j in range(1, len(dp[0])): if word2[i-1] == word1[j-1]: dp[i][j] = min(dp[i-1][j] + 1, dp[i][j-1] + 1, dp[i-1][j-1]) else: dp[i][j] = min(dp[i-1][j] + 1, dp[i][j-1] + 1, dp[i-1][j-1] + 1) return dp[-1][-1]树
建树
根据给定的list按照层次遍历建立树
class TreeNode: def __init__(self, val=0, left=None, right=None): self.val = val self.left = left self.right = rightfrom collections import dequedef build_tree_from_list(values): if not values: return None root = TreeNode(values[0]) queue = deque([root]) index = 1 while queue and index < values.length: node = queue.popleft() if index < len(values) and values[index] is not None: node.left = TreeNode(values[index]) queue.append(node.left) index += 1 if index < len(values) and values[index] is not None: node.right = TreeNode(values[index]) queue.append(node.right) index += 1 return root# 给定的列表values = [5, 4, 8, 11, None, 13, 4, 7, 2, None, None, 5, 1]# 构建二叉树root = build_tree_from_list(values)# 辅助函数:层序遍历以验证树结构def level_order_traversal(root): if not root: return queue = deque([root]) while queue: node = queue.popleft() if node: print(node.val, end=' ') queue.append(node.left) queue.append(node.right) else: print("None", end=' ')print("Level order traversal of the tree:")level_order_traversal(root)LC-103 二叉树锯齿形遍历
给定一个二叉树,返回其节点值的锯齿形层序遍历。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
例如:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回锯齿形层序遍历如下:
[
[3],
[20,9],
[15,7]
]
BFS和DFS,BFS一定使用队列,本题由于有奇偶行的区别,考虑使用双端队列;DFS递归参数要代上层号。
# BFSclass Solution: def zigzagLevelOrder(self, root: TreeNode) -> List[List[int]]: if not root: return [] queue = deque() queue.append(root) flag = 1 res = [] while queue: level = deque() # 每层node存放 for i in range(len(queue)): item = queue.popleft() # 弹出后 做2件事: # 1. 存入 level queue if flag % 2 == 1: level.append(item.val) else: level.appendleft(item.val) # 2. 左右子节点存入 queue if item.left: queue.append(item.left) if item.right: queue.append(item.right) res.append(level) flag += 1 return res# DFSclass Solution: def zigzagLevelOrder(self, root: TreeNode) -> List[List[int]]: res = [] def recursive(root, index): # 递归要把完成的程序栈 return if not root: return if index > len(res): res.append(deque()) if index % 2 == 1: res[index-1].append(root.val) else: res[index-1].appendleft(root.val) recursive(root.left, index + 1) recursive(root.right, index + 1) recursive(root, 1) return [list(item) for item in res]LC-102 二叉树的层序遍历
给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。
示例:
二叉树:[3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回其层序遍历结果:
[
[3],
[9,20],
[15,7]
]
层序遍历BFS一般步骤:
- 边界判断
- 新建deque,加入root
- queue循环当前queue中的长度,并新建每一层的结果存储集level
- 2件事,加入level结果,加入queue以便做下一次遍历
# BFSclass Solution: def levelOrder(self, root: TreeNode) -> List[List[int]]: if not root: return [] queue = deque() queue.append(root) res = [] while queue: level = [] for i in range(len(queue)): node = queue.popleft() level.append(node.val) if node.left: queue.append(node.left) if node.right: queue.append(node.right) res.append(level) return res深度遍历DFS一般步骤:
- 判断边界
- 写遍历函数体,递归要return函数栈
- 对每一个root节点,做2件事:加入到res对应的层中,前序遍历以此递归
# DFSclass Solution: def levelOrder(self, root: TreeNode) -> List[List[int]]: if not root: return [] res = [] def recursive(root, index): if not root: return if index > len(res): res.append([]) res[index - 1].append(root.val) recursive(root.left, index + 1) recursive(root.right, index + 1) recursive(root, 1) return resLC-107 二叉树的层序遍历2
给定一个二叉树,返回其节点值自底向上的层序遍历。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
例如:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回其自底向上的层序遍历为:
[
[15,7],
[9,20],
[3]
]
和102唯一的区别就是存放最终结果的时候是倒序,自底向上累计。
class Solution: def levelOrderBottom(self, root: TreeNode) -> List[List[int]]: if not root: return [] res = [] def recursive(root, index): if not root: return if index > len(res): res.insert(0, []) res[len(res)-index].append(root.val) # 注意append的index是最大行数-当前index=0 recursive(root.left, index + 1) recursive(root.right, index + 1) recursive(root, 1) return resLC-236 二叉树的最近公共祖先
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。
class Solution: def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode': # 后序遍历 if root == p or root == q or root == None: return root left = self.lowestCommonAncestor(root.left, p, q) right = self.lowestCommonAncestor(root.right, p, q) # 得到该节点对应的左右节点后,要决定根据状态返回 root、left、right 哪个节点 if left and right: return root if left == None and right: return right elif right == None and left: return left else: return NoneLC-98 验证二叉搜索树
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
假设一个二叉搜索树具有如下特征:
节点的左子树只包含小于当前节点的数。
节点的右子树只包含大于当前节点的数。
所有左子树和右子树自身必须也是二叉搜索树。
解释: 输入为: [5,1,4,null,null,3,6]。
根节点的值为 5 ,但是其右子节点值为 4 。
中序遍历,BST重要特征是中序遍历后的数组是按顺序的
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution: def isValidBST(self, root: TreeNode) -> bool: if not root: return True self.pre = None def midorder(root): left , right= True , True if root.left: left = midorder(root.left) if self.pre and self.pre.val >= root.val :#前一个节点的值是否小于当前节点的值 return False self.pre = root#记录前一个节点 if root.right: right = midorder(root.right) return left and right return midorder(root)LC-199 二叉树右视图
给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
输入: [1,2,3,null,5,null,4]
输出: [1,3,4]
BFS,层序遍历,遍历到最右边,加入到结果集中。
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution: def rightSideView(self, root: TreeNode) -> List[int]: if not root: return [] queue = deque() queue.append(root) res = [] while queue: n = len(queue) for i in range(len(queue)): node = queue.popleft() if node.left: queue.append(node.left) if node.right: queue.append(node.right) if i == (n - 1): res.append(node.val) return resDFS, 前序遍历,右节点先行
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution: def rightSideView(self, root: TreeNode) -> List[int]: res = [] def dfs(root, deep): if not root: return if deep == len(res): res.append(root.val) deep += 1 dfs(root.right, deep) dfs(root.left, deep) dfs(root, 0) return resLC-101 对称二叉树
给定一个二叉树,检查它是否是镜像对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1
/ \
2 2
/ \ / \
3 4 4 3
DFS,构造递归函数,入参是左右2个的节点。
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution: def isSymmetric(self, root: TreeNode) -> bool: if not root: return True def helper(left, right): if not left and not right: return True if not left or not right or left.val != right.val: return False ans = helper(left.left, right.right) and helper(left.right, right.left) return ans return helper(root.left, root.right)LC-105 从前序与中序遍历序列构造二叉树
给定一棵树的前序遍历 preorder 与中序遍历 inorder。请构造二叉树并返回其根节点。
Input: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
Output: [3,9,20,null,null,15,7]
- 前序遍历确定根节点
- 中序遍历中拿到根节点index,分为左右子树
- 递归作为前序和中序的输入
- 代码整体是前序遍历
将大问题拆解成子问题
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution: def buildTree(self, preorder: List[int], inorder: List[int]) -> TreeNode: if len(inorder) == 0: return None # 跟节点 root = TreeNode(preorder[0]) # 中间节点 mid = inorder.index(preorder[0]) # 左子树 root.left = self.buildTree(preorder[1:mid+1], inorder[:mid]) # 右子树 root.right = self.buildTree(preorder[mid+1:], inorder[mid+1:]) return rootLC-112 路径总和
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum ,判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。
叶子节点 是指没有子节点的节点。
输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
输出:true
输入:root = [1,2], targetSum = 0
输出:false
DFS 递归
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution: def hasPathSum(self, root: Optional[TreeNode], targetSum: int) -> bool: if not root: return False def dfs(root, target): if not root: return False if not root.left and not root.right: if root.val == target: return True else: return False l = dfs(root.left, target - root.val) r = dfs(root.right, target - root.val) return l or r return dfs(root, targetSum)LC-113 路径总和 II
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
叶子节点 是指没有子节点的节点。
输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22
输出:[[5,4,11,2],[5,8,4,5]]
DFS,不需要回溯,没有需要维护的可变状态,不断递归就可
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution: def pathSum(self, root: Optional[TreeNode], targetSum: int) -> List[List[int]]: if not root: return [] def dfs(root, target, path): if not root: return if not root.left and not root.right: if target - root.val == 0: path.append(root.val) res.append(path) dfs(root.left, target - root.val, path + [root.val]) dfs(root.right, target - root.val, path + [root.val]) res = [] dfs(root, targetSum, []) return resLC-124 二叉树中的最大路径和
路径 被定义为一条从树中任意节点出发,沿父节点-子节点连接,达到任意节点的序列。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点 root ,返回其 最大路径和 。
输入:root = [1,2,3]
输出:6
解释:最优路径是 2 -> 1 -> 3 ,路径和为 2 + 1 + 3 = 6
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution: def maxPathSum(self, root: TreeNode) -> int: self.res = float('-inf') def helper(root): if not root: return 0 left = helper(root.left) right = helper(root.right) # inner 内部路径 self.res = max(self.res, root.val + left + right) # outside 需要返回给父节点的外部路径 inner_max = max(left, right) + root.val # inner_max <=0 时返回 0 if inner_max <= 0: return 0 else: return inner_max helper(root) return self.resLC-129 求根节点到叶节点数字之和
给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。
每条从根节点到叶节点的路径都代表一个数字:
例如,从根节点到叶节点的路径 1 -> 2 -> 3 表示数字 123 。
计算从根节点到叶节点生成的 所有数字之和.叶节点 是指没有子节点的节点。
输入:root = [4,9,0,5,1]
输出:1026
解释:
从根到叶子节点路径 4->9->5 代表数字 495
从根到叶子节点路径 4->9->1 代表数字 491
从根到叶子节点路径 4->0 代表数字 40
因此,数字总和 = 495 + 491 + 40 = 1026
前序遍历,先处理root.val * 10
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution: def sumNumbers(self, root: TreeNode) -> int: res = 0 def helper(root, tmp): if not root: return 0 # 前序遍历 tmp = tmp * 10 + root.val; if not root.left and not root.right: return tmp return helper(root.left, tmp) + helper(root.right, tmp) return helper(root, 0)LC-958 二叉树的完全性检验
给定一个二叉树,确定它是否是一个完全二叉树。
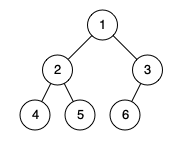
输入:[1,2,3,4,5,6]
输出:true
解释:最后一层前的每一层都是满的(即,结点值为 {1} 和 {2,3} 的两层),且最后一层中的所有结点({4,5,6})都尽可能地向左。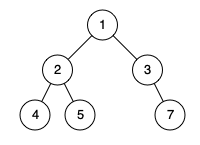
输入:[1,2,3,4,5,null,7]
输出:false
解释:值为 7 的结点没有尽可能靠向左侧。
# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution: def isCompleteTree(self, root: TreeNode) -> bool: if not root: return False queue = deque() queue.append(root) while queue: for i in range(len(queue)): item = queue.popleft() if not item: print(set(queue)) if set(queue) == {None}: return True else: return False queue.append(item.left) queue.append(item.right)LC-104 二叉树的最大深度
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],
后续遍历
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution: def maxDepth(self, root: TreeNode) -> int: def helper(root, deep): if not root: return 0 l = helper(root.left, deep) r = helper(root.right, deep) return 1 + max(l, r) return helper(root, 0)LC-226 反转二叉树
class Solution: def invertTree(self, root: TreeNode) -> TreeNode: if not root: return tmp = root.left root.left = root.right root.right = tmp self.invertTree(root.left) self.invertTree(root.right) return rootLC-114 二叉树展开成链表
给你二叉树的根结点 root ,请你将它展开为一个单链表:
展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null 。
展开后的单链表应该与二叉树 先序遍历 顺序相同。
输入:root = [1,2,5,3,4,null,6]
输出:[1,null,2,null,3,null,4,null,5,null,6]
- 后序遍历,递归
- 左节点换到右节点
- 右节点接到左节点右边
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution: def flatten(self, root: TreeNode) -> None: """ Do not return anything, modify root in-place instead. """ def dfs(root): if not root: return None # 后序遍历 dfs(root.left) dfs(root.right) # 拿到左右节点 l = root.left r = root.right # 对于root来说左节点置空,原左节点置右 root.left = None root.right = l p = root # 遍历当前右节点到最后,右节点街上 while p.right: p = p.right p.right = r dfs(root)LC-230 二叉树搜索树中的第k个小的元素
给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 个最小元素(从 1 开始计数)。
输入:root = [5,3,6,2,4,null,null,1], k = 3
输出:3
BST 搜索树,中序遍历可以得到排序后的序列
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution: def kthSmallest(self, root: TreeNode, k: int) -> int: res = [] def inorder(root): if not root: return [] inorder(root.left) res.append(root.val) inorder(root.right) inorder(root) return res[k-1]LC-662 二叉树最大宽度
给定一个二叉树,编写一个函数来获取这个树的最大宽度。树的宽度是所有层中的最大宽度。这个二叉树与满二叉树(full binary tree)结构相同,但一些节点为空。
每一层的宽度被定义为两个端点(该层最左和最右的非空节点,两端点间的null节点也计入长度)之间的长度。
输入:
1
/
3 2
/ \
5 9
/
6 7
输出: 8
解释: 最大值出现在树的第 4 层,宽度为 8 (6,null,null,null,null,null,null,7)。
层次遍历
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution(object): def widthOfBinaryTree(self, root): """ :type root: TreeNode :rtype: int """ if not root: return 0 queue = [] queue.append([root, 1]) res = 1 while queue: # 一层总数 for i in range(len(queue)): tmp = queue.pop(0) node = tmp[0] index = tmp[1] # calculate base on last queue if node.left: queue.append([node.left, index * 2]) if node.right: queue.append([node.right, index * 2 + 1 ]) if queue: res = max(res, queue[-1][1] - queue[0][1] + 1) return resJZ-26 树的子结构
输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构)
B是A的子结构, 即 A中有出现和B相同的结构和节点值。
例如:
给定的树 A:
3
/
4 5
/
1 2
给定的树 B:
4
/
1
返回 true,因为 B 与 A 的一个子树拥有相同的结构和节点值。
示例 1:
输入:A = [1,2,3], B = [3,1]
输出:false
# Definition for a binary tree node.# class TreeNode:# def __init__(self, x):# self.val = x# self.left = None# self.right = Noneclass Solution: def isSubStructure(self, A: TreeNode, B: TreeNode) -> bool: if not B: return False def helper(nodeA, nodeB): # b没有节点了一定true if not nodeB: return True # a没有节点了一定false if not nodeA: return False # a 和 b 的节点不一样一定false if nodeA.val != nodeB.val: return False return helper(nodeA.left, nodeB.left) and helper(nodeA.right, nodeB.right) def dfs(nodeA): if not nodeA: return False # 找到相同的开头 if nodeA.val == B.val: if helper(nodeA, B): return True return dfs(nodeA.left) or dfs(nodeA.right) return dfs(A)链表
LC-206 反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
class Solution: def reverseList(self, head: ListNode) -> ListNode: if not head or not head.next: return head # 后续节点 last = self.reverseList(head.next) # 1. 前序节点反转 head.next.next = head # 2. 砍掉本身的next指针 head.next = None return lastclass Solution: def reverseList(self, head: ListNode) -> ListNode: pre, cur = None, head while cur: nxt = cur.next # 接到pre后面 cur.next = pre pre = cur cur = nxt return preLC-25 K个一组反转链表
给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表。
k 是一个正整数,它的值小于或等于链表的长度。
如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
输入:head = [1,2,3,4,5], k = 3
输出:[3,2,1,4,5]
class Solution: def reverseKGroup(self, head: ListNode, k: int) -> ListNode: def reverse(left, right): pre, cur = left, left.next # pre 收集结果 first, last = pre, cur while cur != right: nxt = cur.next cur.next = pre pre = cur cur = nxt first.next = pre last.next = right return last dummy = ListNode(-1) dummy.next = head left, right = dummy, head cnt = 0 while right: cnt += 1 right = right.next if cnt % k == 0: left = reverse(left, right) return dummy.next运用翻转链表的子模块,在主模块里的first和last,first 始终表示进行翻转组的前一个,last 表示最终的最后一个节点,其实也就是起始翻转的第一个节点。
K个一组翻转链表要点:
- 构建虚拟头结点,涉及几个一组、快慢、双指针问题,都要涉及到2个指正前进的问题
- 翻转部分子函数,传入的应该是翻转组的前一个和后一个节点,这样可以串联最后的结果
- 子模型是翻转链表,pre实则是收集最终结果,last是该子模块的最后一个节点,也是下一个迭代的起点
LC-92 反转链表2
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left <= right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。
输入:head = [1,2,3,4,5], left = 2, right = 4
输出:[1,4,3,2,5]
链表头插法解题
class Solution: def reverseBetween(self, head: ListNode, left: int, right: int) -> ListNode: dummy_node = ListNode(-1) dummy_node.next = head pre = dummy_node for i in range(left-1): pre = pre.next cur = pre.next # 头插法 for i in range(right - left): nxt = cur.next cur.next = nxt.next nxt.next = pre.next pre.next = nxt return dummy_node.next头插法要点:
- 得到 pre, cur 和 nxt
- cur next 指针指向 nxt 后一个
- nxt next 指针指向 pre 的 next 即之前的头结点
- pre next 指向 nxt
LC-21 合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
链表递归,实则就是回溯
# Definition for singly-linked list.# class ListNode:# def __init__(self, val=0, next=None):# self.val = val# self.next = nextclass Solution: def mergeTwoLists(self, l1: ListNode, l2: ListNode): if not l1: return l2 if not l2: return l1 if l1.val < l2.val: l1.next = self.mergeTwoLists(l1.next, l2) # 回溯 return l1 else: l2.next = self.mergeTwoLists(l2.next, l1) # 回溯 return l2LC-23 合并k个有序链表
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[
1->4->5,
1->3->4,
2->6
]
将它们合并到一个有序链表中得到。1->1->2->3->4->4->5->6
方法一,逐个做合并2个有序链表。
# Definition for singly-linked list.# class ListNode:# def __init__(self, val=0, next=None):# self.val = val# self.next = nextclass Solution: def mergeKLists(self, lists: List[ListNode]) -> ListNode: x = None for i in lists: x = self.mergeTwoLists(x, i) return x # 合并 2 个有序链表模板 def mergeTwoLists(self, l1: ListNode, l2: ListNode): if not l1: return l2 if not l2: return l1 if l1.val < l2.val: l1.next = self.mergeTwoLists(l1.next, l2) # 回溯 return l1 else: l2.next = self.mergeTwoLists(l2.next, l1) # 回溯 return l2方法二,归并排序
class Solution: def mergeKLists(self, lists: List[ListNode]) -> ListNode: if not lists:return n = len(lists) return self.merge(lists, 0, n-1) def merge(self,lists, left, right): if left == right: return lists[left] mid = left + (right - left) // 2 # left, mid l1 = self.merge(lists, left, mid) # mid + 1, right l2 = self.merge(lists, mid+1, right) # 分拆到最后,再做 2 个链表合并 return self.mergeTwoLists(l1, l2) def mergeTwoLists(self,l1, l2): if not l1:return l2 if not l2:return l1 if l1.val < l2.val: l1.next = self.mergeTwoLists(l1.next, l2) return l1 else: l2.next = self.mergeTwoLists(l1, l2.next) return l2LC-141 环形链表
给定一个链表,判断链表中是否有环。
输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。
简单题,快慢指针,相遇即有环
class Solution: def hasCycle(self, head: ListNode) -> bool: dummy = ListNode(-1) dummy.next = head fast, slow = dummy.next, dummy while fast != slow: if not fast or not fast.next: return False fast = fast.next.next slow = slow.next return TrueLC-142 环形链表2
给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
输入:head = [3,2,0,-4], pos = 1
输出:返回索引为 1 的链表节点
解释:链表中有一个环,其尾部连接到第二个节点。
f = 2s (快指针是慢指针速度的2倍)
f = s + nk (快指针比慢指针多走了n次环,环是k)
s = nk,快指针重置为head,相遇即为环的入口
class Solution: def detectCycle(self, head: ListNode) -> ListNode: fast, slow = head, head while True: if not fast or not fast.next: return None fast = fast.next.next slow = slow.next if fast == slow: break fast = head while fast != slow: fast = fast.next slow = slow.next return slowLC-160 相交链表
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。
图示两个链表在节点 c1 开始相交:
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at ‘8’
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
class Solution: def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode: a = headA b = headB while a != b: if a: a = a.next else: a = headB if b: b = b.next else: b = headA return aLC-19 删除链表的倒数第 N 个结点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
进阶:你能尝试使用一趟扫描实现吗?
输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
# Definition for singly-linked list.# class ListNode:# def __init__(self, val=0, next=None):# self.val = val# self.next = nextclass Solution: def removeNthFromEnd(self, head: ListNode, n: int) -> ListNode: dummy = ListNode(0) dummy.next = head #step1: 快指针先走n步 slow, fast = dummy, dummy for _ in range(n): fast = fast.next #step2: 快慢指针同时走,直到fast指针到达尾部节点,此时slow到达倒数第N个节点的前一个节点 while fast and fast.next: slow, fast = slow.next, fast.next #step3: 删除节点,并重新连接 slow.next = slow.next.next return dummy.next LC-143 重排链表
给定一个单链表 L 的头节点 head ,单链表 L 表示为:
L0 → L1 → … → Ln-1 → Ln
请将其重新排列后变为:
L0 → Ln → L1 → Ln-1 → L2 → Ln-2 → …
不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
输入: head = [1,2,3,4]
输出: [1,4,2,3]
输入: head = [1,2,3,4,5]
输出: [1,5,2,4,3]
三步:找中点;反转链表;合并有序链表
# Definition for singly-linked list.# class ListNode:# def __init__(self, val=0, next=None):# self.val = val# self.next = nextclass Solution: def reorderList(self, head: ListNode) -> None: """ Do not return anything, modify head in-place instead. """ if not head: return None mid = self.find_mid(head) l1 = head l2 = mid.next # 切断 mid.next = None l2 = self.reverse_list(l2) return self.merge(l1, l2) def find_mid(self, head): if head is None or head.next is None: return head slow,fast = head, head.next while fast and fast.next: slow=slow.next fast=fast.next.next return slow def reverse_list(self, head): pre, cur = None, head while cur: nxt = cur.next cur.next = pre pre = cur cur = nxt return pre def merge(self, l1, l2): head = l1 while l2: l1_nxt = l1.next l2_nxt = l2.next l1.next = l2 l2.next = l1_nxt l1 = l1_nxt l2 = l2_nxt return headLC-234 回文链表
请判断一个链表是否为回文链表.
输入: 1->2->2->1
输出: true
3种方法:
- 把链表变成数组,用双指针,缺点额外空间
- 链表后序递归
- 快慢双指针找中点后,后半段反转链表
# 第二种 class Solution: def isPalindrome(self, head: ListNode) -> bool: self.left = head def traverse(right): if not right: return True res = traverse(right.next) if res and self.left.val == right.val: res = True else: res = False self.left = self.left.next return res return traverse(head)# 第三种class Solution: def isPalindrome(self, head: ListNode) -> bool: if not head or not head.next: return True # 找中点 fast = head slow = head while fast and fast.next: slow = slow.next fast = fast.next.next if not fast: mid = slow else: mid = slow.next # 反转链表 right_head = mid pre = None cur = right_head while cur: nxt = cur.next cur.next = pre pre = cur cur = nxt # 比较相等 right = pre left = head while right and left: if right.val != left.val: return False right = right.next left = left.next return TrueLC-148 排序链表
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
进阶:
你可以在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序吗?
示例 1:
输入:head = [4,2,1,3]
输出:[1,2,3,4]
nlogn 复杂度,需要考虑 快排、归并、堆等
class Solution: # 归并排序 def sortList(self, head: ListNode) -> ListNode: if not head or not head.next: return head left_end = self.find_mid(head) mid = left_end.next left_end.next = None # 左边 None 结束,右边 mid 开始 left, right = self.sortList(head), self.sortList(mid) return self.merged(left, right) # 快慢指针查找链表中点 def find_mid(self, head): if head is None or head.next is None: return head slow,fast = head, head.next while fast and fast.next: slow=slow.next fast=fast.next.next return slow # 合并有序链表 def merged(self, left, right): res = ListNode() h = res while left and right: if left.val < right.val: h.next= left left = left.nex else: h.next = right right = right.next h = h.next # 判断 left 和 right 是否是 None h.next = left if left else right return res.nextLC-82 删除排序链表中的重复元素2
存在一个按升序排列的链表,给你这个链表的头节点 head ,请你删除所有重复的元素,使每个元素 只出现一次 。
返回同样按升序排列的结果链表。
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
# Definition for singly-linked list.# class ListNode:# def __init__(self, val=0, next=None):# self.val = val# self.next = nextclass Solution: def deleteDuplicates(self, head: ListNode) -> ListNode: dummy = ListNode(None) dummy.next = head p = dummy while head and head.next: if p.next.val != head.next.val: p = p.next head = head.next else: while head and head.next and p.next.val==head.next.val: head = head.next # p 的 next 要指定 head 的下一个 p.next = head.next head = head.next return dummy.next组织 tail,2 步 head next 避免 插入相同的
class Solution: def deleteDuplicates(self, head: ListNode) -> ListNode: tail = dummy = ListNode(-1) while head: if head.next == None or head.val != head.next.val: tail.next = head; tail = tail.next while head.next and head.val == head.next.val: head = head.next head = head.next tail.next = None return dummy.nextLC-83 删除排序链表中的重复元素
存在一个按升序排列的链表,给你这个链表的头节点 head ,请你删除所有重复的元素,使每个元素 只出现一次 。
返回同样按升序排列的结果链表。
输入:head = [1,1,2,3,3]
输出:[1,2,3]
# Definition for singly-linked list.# class ListNode:# def __init__(self, val=0, next=None):# self.val = val# self.next = nextclass Solution: def deleteDuplicates(self, head: ListNode) -> ListNode: if not head: return None dummy = ListNode(-10000) dummy.next = head p = dummy # p 落后 head 一个节点位置 while head: if p.val != head.val: p.next = head p = p.next head = head.next p.next = None return dummy.nextLC-24 两两交换链表中的节点
给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。
你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
示例 1:
输入:head = [1,2,3,4]
输出:[2,1,4,3]
递归:
class Solution: def swapPairs(self, head: ListNode) -> ListNode: if not head or not head.next: return headx newHead = head.next head.next = self.swapPairs(newHead.next) newHead.next = head return newHead迭代
class Solution: def swapPairs(self, head: ListNode) -> ListNode: dummyHead = ListNode(0) dummyHead.next = head temp = dummyHead while temp.next and temp.next.next: node1 = temp.next node2 = temp.next.next temp.next = node2 node1.next = node2.next node2.next = node1 temp = node1 return dummyHead.nextLC-328 奇偶链表
给定一个单链表,把所有的奇数节点和偶数节点分别排在一起。请注意,这里的奇数节点和偶数节点指的是节点编号的奇偶性,而不是节点的值的奇偶性。
请尝试使用原地算法完成。你的算法的空间复杂度应为 O(1),时间复杂度应为 O(nodes),nodes 为节点总数。
示例 1:
输入: 1->2->3->4->5->NULL
输出: 1->3->5->2->4->NULL
示例 2:
输入: 2->1->3->5->6->4->7->NULL
输出: 2->3->6->7->1->5->4->NULL
# class ListNode:# def __init__(self, val=0, next=None):# self.val = val# self.next = nextclass Solution: def oddEvenList(self, head: ListNode) -> ListNode: if not head: return None odd = head even = head.next evenhead = head.next while even and even.next: odd.next = even.next odd = odd.next even.next = odd.next even = even.next odd.next = evenhead return headLC-61 旋转链表
给你一个链表的头节点 head ,旋转链表,将链表每个节点向右移动 k 个位置。
示例 1:
输入:head = [1,2,3,4,5], k = 2
输出:[4,5,1,2,3]
分解为3个题:1.长度,2.末尾第n个节点,3.切割链表
# Definition for singly-linked list.# class ListNode:# def __init__(self, val=0, next=None):# self.val = val# self.next = nextclass Solution: def rotateRight(self, head: Optional[ListNode], k: int) -> Optional[ListNode]: length = 0 cur = head while cur: length += 1 cur = cur.next if length < 1: # 注意 return head k = k % length if k == 0: return head dummy = ListNode(0) dummy.next = head fast, slow = dummy, dummy for _ in range(k): fast = fast.next while fast.next: slow = slow.next fast = fast.next newHead = slow.next slow.next = None fast.next = head return newHeadLC-86 分隔链表
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
示例 1:
输入:head = [1,4,3,2,5,2], x = 3
输出:[1,2,2,4,3,5]
# Definition for singly-linked list.# class ListNode:# def __init__(self, val=0, next=None):# self.val = val# self.next = nextclass Solution: def partition(self, head: ListNode, x: int) -> ListNode: small, large = ListNode(), ListNode() sm = small lg = large while head: if head.val < x: sm.next = head sm = sm.next else: lg.next = head lg = lg.next head = head.next lg.next = None sm.next = large.next return small.nextLC-382 链表随机节点
给定一个单链表,随机选择链表的一个节点,并返回相应的节点值。保证每个节点被选的概率一样。
进阶:
如果链表十分大且长度未知,如何解决这个问题?你能否使用常数级空间复杂度实现?
示例:
// 初始化一个单链表 [1,2,3].
ListNode head = new ListNode(1);
head.next = new ListNode(2);
head.next.next = new ListNode(3);
Solution solution = new Solution(head);
// getRandom()方法应随机返回1,2,3中的一个,保证每个元素被返回的概率相等。
solution.getRandom();
蓄水池采样,每次前进概率为 1/k,如果没有采样到,则前述保留的概率为 1/k * k/k+1 …
也为 1/k。
# Definition for singly-linked list.# class ListNode:# def __init__(self, val=0, next=None):# self.val = val# self.next = nextimport randomclass Solution: def __init__(self, head: ListNode): self.head = head def getRandom(self) -> int: count = 0 reserve = 0 cur = self.head while cur: count += 1 rand = random.randint(1,count) if rand == count: reserve = cur.val # 1 * 1/2 * 2/3 * 3/4 ... cur = cur.next return reserve数学
高频-1 计算π
假设循环次数可以无限,如何得到比较精确的π。
- 蒙特卡洛估计法,正方形中随机采样看落在圆内的概率
import randomdef monte_carlo_pi(num_samples): inside_circle = 0 for _ in range(num_samples): x, y = random.random(), random.random() # 生成两个随机数 x 和 y,范围在 [0, 1) 之间 if x**2 + y**2 <= 1: # 检查点 (x, y) 是否在单位圆内 inside_circle += 1 # 如果在圆内,计数器加 1 return (inside_circle / num_samples) * 4 # 计算落在圆内的点的比例,并乘以 4 估算 πnum_samples = 1000000pi_estimate = monte_carlo_pi(num_samples)print(f"Estimated Pi: {pi_estimate}")- 莱布尼茨法,无限级数=π/4
def process(n): pie = 0 for i in range(n): numerater = (-1) ** i denumerater = 2 * i + 1 number = numerater / denumerater pie += number return 4 * pieres = process(100000)print(res)LC-69 x 的平方根
给你一个非负整数 x ,计算并返回 x 的 算术平方根。由于返回类型是整数,结果只保留 整数部分,小数部分将被舍去.
注意:不允许使用任何内置指数函数和算符,例如 pow(x, 0.5) 或者 x ** 0.5
示例 1:
输入:x = 4 输出:2
示例 2:
输入:x = 8
输出:2
解释:8 的算术平方根是 2.82842…, 由于返回类型是整数,小数部分将被舍去。
class Solution(object): def mySqrt(self, x): """ :type x: int :rtype: int """ left, right = 0, x while left <= right: mid = left + (right - left) // 2 if mid ** 2 == x: return mid if mid ** 2 < x: left = mid + 1 else: right = mid - 1 return left - 1LC-2 两数相加
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[7,0,8]
解释:342 + 465 = 807.
输入:l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9]
输出:[8,9,9,9,0,0,0,1]
# Definition for singly-linked list.# class ListNode:# def __init__(self, val=0, next=None):# self.val = val# self.next = nextclass Solution: def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode: head = dummy = ListNode() curry = 0 sum = 0 res = 0 # 当l1和l2都为None时,需要检查curry进位符是否还为1 while curry or l1 or l2: if l1: l1_val = l1.val else: l1_val = 0 if l2: l2_val = l2.val else: l2_val = 0 sum = l1_val + l2_val + curry res = sum % 10 curry = sum // 10 dummy.next = ListNode(res) dummy, l1, l2 = dummy.next, l1.next if l1 else None, l2.next if l2 else None return head.next链表需要时刻检查链表是否为None,新建2个dummy节点,一个随迭代往后,一个指向开头用于返回结果。
LC-8 字符串转换整数 (atoi)
请你来实现一个 myAtoi(string s) 函数,使其能将字符串转换成一个 32 位有符号整数(类似 C/C++ 中的 atoi 函数)。
函数 myAtoi(string s) 的算法如下:
读入字符串并丢弃无用的前导空格
检查下一个字符(假设还未到字符末尾)为正还是负号,读取该字符(如果有)。 确定最终结果是负数还是正数。 如果两者都不存在,则假定结果为正。
读入下一个字符,直到到达下一个非数字字符或到达输入的结尾。字符串的其余部分将被忽略。
将前面步骤读入的这些数字转换为整数(即,“123” -> 123, “0032” -> 32)。如果没有读入数字,则整数为 0 。必要时更改符号(从步骤 2 开始)。
如果整数数超过 32 位有符号整数范围 [−231, 231 − 1] ,需要截断这个整数,使其保持在这个范围内。具体来说,小于 −231 的整数应该被固定为 −231 ,大于 231 − 1 的整数应该被固定为 231 − 1 。
返回整数作为最终结果。
输入:s = " -42"
输出:-42
解释:
第 1 步:" -42"(读入前导空格,但忽视掉)
^
第 2 步:" -42"(读入 ‘-’ 字符,所以结果应该是负数)
^
第 3 步:" -42"(读入 “42”)
^
解析得到整数 -42 。
由于 “-42” 在范围 [-231, 231 - 1] 内,最终结果为 -42 。
需要严格注意这个读入的顺序
class Solution: def myAtoi(self, s: str) -> int: str=s.lstrip() if len(str)==0: return 0 # 不断改写 last=0 #如果有符号设置起始位置2,其余的为1 i=2 if str[0]=='-'or str[0]=='+' else 1 #循环,直到无法强转成int,跳出循环 while i <= len(str): try: last=int(str[:i]) i+=1 except: break if last<-2**31: return -2147483648 if last>2**31-1: return 2147483647 return last启发另一种索引方式,索引最后一个位置,而非索引对应位置,这样可以和题目要求对应,作用到下一个之前
LC-50 Pow(x, n)
实现 pow(x, n) ,即计算 x 的 n 次幂函数(即,xn)。
示例 1:
输入:x = 2.00000, n = 10
输出:1024.00000
示例 3:
输入:x = 2.00000, n = -2
输出:0.25000
解释:2-2 = 1/22 = 1/4 = 0.25
class Solution: def myPow(self, x: float, n: int) -> float: def quickMul(N): if N == 0: return 1.0 y = quickMul(N // 2) return y * y if N % 2 == 0 else y * y * x return quickMul(n) if n >= 0 else 1.0 / quickMul(-n)快速幂模板:
# 实数def qpow(a, n): ans = 1 while n > 0: if (n & 1): ans *= a a *= a n >>= 1 return ans# 矩阵import numpy as npdef pow(n): a = np.array([[1,0],[0,1]]) b = np.array([[1,1],[1,0]]) while(n > 0): if (n % 2 == 1): a = np.dot(b, a) b = np.dot(b, b) n >>= 1 return a[0][1]class Solution: def myPow(self, x: float, n: int) -> float: if n < 0: x, n = 1/x, n*(-1) return qpow(x, n)LC-400 第 N 位数字
给你一个整数 n ,请你在无限的整数序列 [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, …] 中找出并返回第 n 位数字。
示例 1:
输入:n = 3
输出:3
示例 2:
输入:n = 11
输出:0
解释:第 11 位数字在序列 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, … 里是 0 ,它是 10 的一部分。
第一行共有 1092 个数
第二行公有 101093 个数
第三行公有 1010109*4 个数
好了规律出来了:
假设初始标记count = 1
每行总数字为:10**count * 9 * (count+1)
另外关于整除后的余数:
如果没有余数,那结果就是基数(10count) + 商 - 1,然后获取这个数的最后一个数字即可
如果有余数,那结果就是基数(10count) + 商,获取到当前的数字,然后 余数-1 找到对应index返回即可
class Solution: def findNthDigit(self, n: int) -> int: if n < 10: return n n -= 9 count = 1 while True: num = 10 ** count * 9 * (count + 1) if n > num: n -= num count += 1 else: i, j = divmod(n, (count + 1)) if not j: return int(str(10 ** count + i - 1)[-1]) else: return int(str(10 ** count + i)[j - 1])LC-43 字符串相乘
给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式。
示例 1:
输入: num1 = “2”, num2 = “3”
输出: “6”
示例 2:
输入: num1 = “123”, num2 = “456”
输出: “56088”
class Solution: def multiply(self, num1: str, num2: str) -> str: n1 = len(num1) n2 = len(num2) num2_int = int(num2) res = 0 #n1 按位倒序与n2相乘,拿到对应位置作为10的power for i in range(n1-1, -1, -1): weight = n1- 1 - i num1_new = int(num1[i]) res += num1_new * 10 ** weight * num2_int return str(res)LC-470 用 Rand7() 实现 Rand10()
已有方法 rand7 可生成 1 到 7 范围内的均匀随机整数,试写一个方法 rand10 生成 1 到 10 范围内的均匀随机整数。
不要使用系统的 Math.random() 方法.
示例 1:
输入: 1
输出: [7]
示例 2:
输入: 2
输出: [8,4]
小数表示大数:(rand7()-1) × 7 + rand7() = result
(rand_x() - 1) × origin_number + rand_y()
可以等概率的生成[1, X * Y]范围的随机数
class Solution: def rand10(self): """ :rtype: int """ # 已知 rand_N() 可以等概率的生成[1, N]范围的随机数 # 那么: # (rand_X() - 1) × Y + rand_Y() ==> 可以等概率的生成[1, X * Y]范围的随机数 # 即实现了 rand_XY() while True: num = (rand7() - 1) * 7 + rand7() if num <= 40: return num % 10 + 1LC-12 整数转罗马数字
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。
X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。
C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。
给你一个整数,将其转为罗马数字。
哈希表
class Solution: def intToRoman(self, num: int) -> str: hashmap = {1000:'M', 900:'CM', 500:'D', 400:'CD', 100:'C', 90:'XC', 50:'L', 40:'XL', 10:'X', 9:'IX', 5:'V', 4:'IV', 1:'I' } res = '' for i in hashmap.keys(): count = num // i if count > 0: res += ''.join([hashmap[i]] * count) num = num % i return res滑动窗口
滑动窗口通用模板:
need, window = {}, {}for c in t: 记录need # 视具体问题而定,用于判断窗口包含的字串是否满足题目要求left, right = 0, 0 # 初始化左右指针,窗口是左闭右开区间,[left, right)while right < len(s): c = s[right] right += 1 更新窗口数据 while 满足窗口收缩条件: 记录优化后的结果 d = s[left] left += 1 更新窗口数据return 结果LC-3 无重复字符的最长子串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: s = “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
class Solution: def lengthOfLongestSubstring(self, s: str) -> int: res = 0 window = dict() left, right = 0, 0 while right < len(s): cur = s[right] # 先加1往后走 window[cur] = window.get(cur, 0) + 1 right += 1 # 更新 while window[cur] > 1: if s[left] in window.keys(): window[s[left]] -= 1 left += 1 res = max(res, right - left) return res LC-76 最小覆盖子串
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 “” 。
输入:s = “ADOBECODEBANC”, t = “ABC”
输出:“BANC”
滑动窗口的基本模式:
- 初始化的 min_len 为 inf float
- 记住只有在need字典中的key才会影响最终结果,不在的话就直接right++或者left–
- match标志位表示这一位的need和window的key是不是值相等
class Solution: def minWindow(self, s: str, t: str) -> str: # 初始化 start, min_len = 0, float('Inf') left, right = 0, 0 need = Counter(t) window = collections.defaultdict(int) match = 0 # right while right < len(s): # 拿出 right 指针 c1 = s[right] if need[c1] > 0: # 匹配后match+1 window[c1] += 1 if window[c1] == need[c1]: match += 1 right += 1 while match == len(need): # 更新结果 if right - left < min_len: min_len = right - left start = left # 优化结果,更新window字典 c2 = s[left] if need[c2] > 0: window[c2] -= 1 if window[c2] < need[c2]: match -= 1 left += 1 return s[start:start+min_len] if min_len != float('Inf') else ""LC-239 滑动窗口最大值
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回滑动窗口中的最大值。
示例 1:
输入:nums = [1,3,-1,-3,5,3,6,7], k = 3
输出:[3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7
单调队列,新的元素,检查是否大于最后一个,满足pop掉末尾的,上浮;判断第一个是否不在窗口,popleft。
class Solution: def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]: from collections import deque window = deque() res = [] for i in range(len(nums)): while window and nums[i] > nums[window[-1]]: window.pop() window.append(i) if window[0] <= i - k: window.popleft() if i - k + 1 >= 0: res.append(nums[window[0]]) return resLC-209 长度最小的子数组
给定一个含有 n 个正整数的数组和一个正整数 target 。
找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 [numsl, numsl+1, …, numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。
示例 1:
输入:target = 7, nums = [2,3,1,2,4,3]
输出:2
解释:子数组 [4,3] 是该条件下的长度最小的子数组。
经典滑动窗口题,用left和right来划定窗口
class Solution: def minSubArrayLen(self, target: int, nums: List[int]) -> int: left, right = 0, 0 bst = float('Inf') while right < len(nums): cur = nums[right] sum_ans = sum(nums[left:right+1]) if sum_ans < target: right += 1 while sum_ans >= target and left <= right: gap = right - left + 1 left += 1 sum_ans = sum(nums[left:right+1]) if gap < bst: bst = gap if bst == float('Inf'): return 0 else: return bstLC-340 至多包含k个不同字符的最长子串
给定一个字符串 s ,找出 至多 包含 k 个不同字符的最长子串 T。
示例1:
输入: s = “eceba”, k = 2
输出: 3
解释: 则 T 为 “ece”,所以长度为 3。
class Solution: def lengthOfLongestSubstringKDistinct(self, s: str, k: int) -> int: Dict = {} count = 0 left, right = 0, 0 res = 0 while(right < len(s)): if s[right] not in Dict: Dict[s[right]] = 1 else: Dict[s[right]] += 1 if Dict[s[right]] == 1: count += 1 # 小于k是结果 if count <= k: res = max(res, right - left + 1) # 大于k是需要优化的结果 else: while(count > k and left <= right): Dict[s[left]] -= 1 if Dict[s[left]] == 0: count -= 1 left += 1 # 优化后再更新一遍结果 res = max(res, right - left + 1) # 继续向后遍历 right += 1 return res二分查找
二分查找模型:
# 常规def binarySearch(nums, target): if len(nums) == 0: return -1 left, right = 0, len(nums) - 1 while(left <= right): mid = left + (right - left) // 2 if nums[mid] == target: return mid elif nums[mid] > target: right = mid - 1 # -1 强制保证 elif nums[mid] < target: left = mid + 1 return -1# 最左边界, right = mid,返回leftdef binarySearchLeft(nums, target): if len(nums) == 0: return -1 left, right = 0, len(nums) - 1 while(left <= right): mid = left + (right - left) // 2 if nums[mid] >= target: right = mid - 1 else: left = mid + 1 if left >= len(nums) or nums[left] != target: return -1 return left# 最右边界,def binarySearchRight(nums, target): if len(nums) == 0: return -1 left, right = 0, len(nums) - 1 while (left <= right): mid = left + (right - left) // 2 if nums[mid] <= target: left = mid + 1 else: right = mid - 1 if right < 0 or nums[right] != target: return -1 return rightLC-33 搜索旋转排序数组
整数数组 nums 按升序排列,数组中的值 互不相同 。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k+1], …, nums[n-1], nums[0], nums[1], …, nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,5,6,7] 在下标 3 处经旋转后可能变为 [4,5,6,7,0,1,2] 。给你旋转后 的数组 nums 和一个整数 target ,如果 nums 中存在这个目标值 target ,则返回它的下标,否则返回 -1 。
示例 1:
输入:nums = [4,5,6,7,0,1,2], target = 0
输出:4
示例 2:
输入:nums = [4,5,6,7,0,1,2], target = 3
输出:-1
class Solution(object): def search(self, nums, target): """ :type nums: List[int] :type target: int :rtype: int """ left = 0 right = len(nums) - 1 while left <= right: mid = left + (right - left) // 2 if nums[mid] == target: return mid if nums[mid] >= nums[left]: # 在左半区间,要定新的right,left一定带等于 # [left, target, mid] right = mid # [left, target, mid) right = mid - 1 if nums[left] <= target and target <= nums[mid]: right = mid # 在右半区间,要定新的left, # (mid, target, right), left = mid + 1 else: left = mid + 1 else: # 在右半区间,要定新的left,right一定带等于 # (mid, target, right] left = mid + 1 # [mid, target, right] left = mid if nums[mid] < target and target <= nums[right]: left = mid + 1 # 在左半区间,要定新的right # (lfet, target, right), right = mid - 1 else: right = mid - 1 return -1LC-163 寻找峰值
峰值元素是指其值大于左右相邻值的元素。
给你一个输入数组 nums,找到峰值元素并返回其索引。数组可能包含多个峰值,在这种情况下,返回 任何一个峰值 所在位置即可。
你可以假设 nums[-1] = nums[n] = -∞ 。
示例 2:
输入:nums = [1,2,1,3,5,6,4]
输出:1 或 5
解释:你的函数可以返回索引 1,其峰值元素为 2;或者返回索引 5,其峰值元素为 6。
class Solution: def findPeakElement(self, nums: List[int]) -> int: if len(nums) <= 2: return nums.index(max(nums)) left = 0 right = len(nums) - 1 while left < right: mid = (left + right) // 2 if nums[mid] > nums[mid + 1]: right = mid else: left = mid + 1 return leftLC-240 搜索二维矩阵 II
编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性:
每行的元素从左到右升序排列。
每列的元素从上到下升序排列。
输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 5
输出:true
Trick: 以右上角的值作为起点,大于target往下走,小于target往左走。
class Solution: def searchMatrix(self, matrix: List[List[int]], target: int) -> bool: if len(matrix) <= 1 and len(matrix[0]) <= 1: return matrix[0][0] == target row, col = 0, len(matrix[0]) - 1 while 0 <= row < len(matrix) and 0 <= col < len(matrix[0]): if target < matrix[row][col]: col -= 1 elif target > matrix[row][col]: row += 1 else: return True return FalseLC-31 下一个排列
实现获取 下一个排列 的函数,算法需要将给定数字序列重新排列成字典序中下一个更大的排列(即,组合出下一个更大的整数)。
如果不存在下一个更大的排列,则将数字重新排列成最小的排列(即升序排列)。必须原地修改,只允许使用额外常数空间。
示例 1:
输入:nums = [1,2,3]
输出:[1,3,2]
示例 2:
输入:nums = [3,2,1]
输出:[1,2,3]
需要原地排序,
- 找到第一个 左边 < 右边 的左边index i
- 从尾部开始遍历,找到第一个 右边 > 左边i的 index j
- 交换 nums[i] 和 nums[j]
- 对于 i+1 部分整体反转
class Solution: def nextPermutation(self, nums): # 1.从后往前找,找相邻2个升序(i, i+1) i = len(nums) - 2 while i >= 0 and nums[i] >= nums[i+1]: i -= 1 # 2. 防止整体都要换位置 if i >= 0: j = len(nums) - 1 # 3. 从后往前找,第一个比i大的j while nums[j] <= nums[i]: j -= 1 nums[i], nums[j] = nums[j], nums[i] # 4. 排序 i+1 后面的部分,整体反转 nums[i+1:] = sorted(nums[i+1:])LC-34 在排序数组中查找元素的第一个和最后一个位置
给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
示例 1:
输入:nums = [5,7,7,8,8,10], target = 8
输出:[3,4]
class Solution: def searchRange(self, nums: List[int], target: int) -> List[int]: def leftbound(nums, target): if len(nums) == 0: return -1 left, right = 0, len(nums) while(left < right): mid = left + (right - left) // 2 if nums[mid] >= target: right = mid else: left = mid + 1 return left def rightbound(nums, target): if len(nums) == 0: return -1 left, right = 0, len(nums) while(left < right): mid = left + (right - left) // 2 if nums[mid] <= target: left = mid + 1 else: right = mid return left - 1 lb = leftbound(nums, target) rb = rightbound(nums, target) if len(nums) == 0: return [-1, -1] if lb == len(nums) or nums[lb] != target: return [-1, -1] return [lb, rb]LC-287 寻找重复数
给定一个包含 n + 1 个整数的数组 nums ,其数字都在 1 到 n 之间(包括 1 和 n),可知至少存在一个重复的整数。
假设 nums 只有 一个重复的整数 ,找出 这个重复的数 。
你设计的解决方案必须不修改数组 nums 且只用常量级 O(1) 的额外空间。
示例 1:
输入:nums = [1,3,4,2,2]
输出:2
示例 2:
输入:nums = [3,1,3,4,2]
输出:3
注意条件是n+1个在1到n之间的数,比较和计算小于mid的坐标数,来确定重复在左还是在右,抽屉原理
class Solution: def findDuplicate(self, nums: List[int]) -> int: left = 0 right = len(nums) - 1 while left < right: mid = left + (right - left ) // 2 # 计数, 找小于等于mid的个数 cnt = 0 for num in nums: if num <= mid: cnt += 1 # <= 说明 重复元素在右半边 if cnt <= mid: left = mid + 1 else: right = mid return leftLC-153 寻找旋转排序数组中的最小值
已知一个长度为 n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后,得到输入数组。例如,原数组 nums = [0,1,2,4,5,6,7] 在变化后可能得到:
若旋转 4 次,则可以得到 [4,5,6,7,0,1,2]
若旋转 7 次,则可以得到 [0,1,2,4,5,6,7]
注意,数组 [a[0], a[1], a[2], …, a[n-1]] 旋转一次 的结果为数组 [a[n-1], a[0], a[1], a[2], …, a[n-2]] 。
给你一个元素值 互不相同 的数组 nums ,它原来是一个升序排列的数组,并按上述情形进行了多次旋转。请你找出并返回数组中的 最小元素 。
你必须设计一个时间复杂度为 O(log n) 的算法解决此问题。
示例 1:
输入:nums = [3,4,5,1,2]
输出:1
解释:原数组为 [1,2,3,4,5] ,旋转 3 次得到输入数组。
最小值:
class Solution: def findMin(self, nums: List[int]) -> int: # 左闭右闭区间,如果用右开区间则不方便判断右值 left, right = 0, len(nums) - 1 while left < right: # 中值 > 右值,最小值在右半边,收缩左边界 mid = left + (right - left) // 2 if nums[mid] > nums[right]: # 因为中值 > 右值,中值肯定不是最小值,左边界可以跨过mid left = mid + 1 # 明确中值 < 右值,最小值在左半边,收缩右边界 elif nums[mid] < nums[right]: # 因为中值 < 右值,中值也可能是最小值,右边界只能取到mid处 right = mid return nums[left] 存在重复时的最小值 (lc-154):
class Solution: def findMin(self, nums: List[int]) -> int: left, right = 0, len(nums) - 1 while left < right: mid = left + (right - left) // 2 if nums[mid] > nums[right]: left = mid + 1 elif nums[mid] < nums[right]: right = mid else: right -= 1 return nums[left]最大值:
class Solution: def findMin(self, nums: List[int]) -> int: left, right = 0, len(nums) - 1 while left < right: # 先加一再除,mid更靠近右边的right mid = left + (right - left) // 2 if nums[left] < nums[mid]: # 向右移动左边界 left = mid elif nums[left] > nums[mid]: # 向左移动右边界 right = mid - 1 return nums[right]回溯
回溯通用模板:
result = []def backtrack(路径, 选择列表): if 满足结束条件: result.add(路径) return for 选择 in 选择列表: 做选择 backtrack(路径, 选择列表) 撤销选择LC-46 全排列
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
class Solution: def permute(self, nums: List[int]): if not nums: return [] # 最终结果集 res = [] def dfs(remain,path): if not remain: res.append(path) return size = len(remain) for _ in range(size): path.append(remain.pop(0)) dfs(remain,path[:]) remain.append(path.pop()) dfs(nums,[]) return res回溯法的终极条件是,全局维护一个可变的状态,所以需要不断的选择和撤销操作。
但是如果不存在可变状态,只是作为函数的传参,就不需要撤销操作了,一切都是函数的递归调用。如下
class Solution(object): # DFS def permute(self, nums): res = [] self.dfs(nums, [], res) return res def dfs(self, nums, path, res): if not nums: res.append(path) # return # backtracking for i in range(len(nums)): self.dfs(nums[:i]+nums[i+1:], path+[nums[i]], res)LC-78 子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
class Solution: def subsets(self, nums: List[int]) -> List[List[int]]: res = [] def dfs(path, i): res.append(path) # 不能重复 用j+1向后遍历 没有回溯 直接是dfs for j in range(i, len(nums)): dfs(path+[nums[j]], j+1) dfs([], 0) return res清楚版:
class Solution: def subsets(self, nums: List[int]) -> List[List[int]]: res = [] def dfs(i, remain, path): res.append(path) size = len(remain) for j in range(i, size): path.append(nums[j]) # 下一次迭代 j+1 dfs(j+1, remain, path[:]) path.pop() dfs(0,nums,[]) return resLC-77 组合
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
示例 1:
输入:n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
class Solution: def combine(self, n: int, k: int) -> List[List[int]]: nums = [i for i in range(1, n+1)] res = [] def dfs(i, path): if len(path) == k: res.append(path) return for j in range(i, len(nums)): # 压入 path.append(nums[j]) # 迭代,当前index往后一位开始迭代 dfs(j+1, path[:]) # 弹出 path.pop() dfs(0, []) return res上述三题为所有回溯题都会沿用的模板,不要去想回溯的过程,直接调用模板
LC-39 组合总和
给定一个无重复元素的正整数数组 candidates 和一个正整数 target ,找出 candidates 中所有可以使数字和为目标数 target 的唯一组合。
输入: candidates = [2,3,6,7], target = 7
输出: [[7],[2,2,3]]
输入: candidates = [2,3,5], target = 8
输出: [[2,2,2,2],[2,3,3],[3,5]]
三要素:
- path 记录走过的节点
- remain 剩余的array,用index索引,或者不断pop remain的数组
- 判断结果符合,可以借助排序来避免剪枝
class Solution: def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]: res = [] candidates.sort() if target < min(candidates): return res def dfs(start, path, gap): if gap == 0: res.append(path) return if gap < min(candidates): return for i in range(start, len(candidates)): path.append(candidates[i]) dfs(i, path[:], gap - candidates[i]) path.pop() dfs(0, [], target) return resLC-22 括号生成
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
有效括号组合需满足:左括号必须以正确的顺序闭合。
示例 1:
输入:n = 3
输出:[“((()))”,“(()())”,“(())()”,“()(())”,“()()()”]
DFS + 剪枝,不需要维护一个状态:
class Solution: def generateParenthesis(self, n: int) -> List[str]: if n == 0: return [] res = [] def dfs(cur, left, right): if left == n and right == n: res.append(cur) if left < n: dfs(cur + "(", left + 1, right) # 如果右括号比左括号多,一定不能构成有效括号 if left > right: dfs(cur + ")", left, right + 1) dfs("", 0, 0) return res回溯,需要维护一个path状态
class Solution: def generateParenthesis(self, n: int) -> List[str]: def backtrace(left, right, path): if left == n and right == n: res.append(''.join(path)) return if left < n: path.append('(') backtrace(left + 1, right, path[:]) path.pop() if left > right: path.append(")") backtrace(left, right + 1, path[:]) path.pop() res = [] backtrace(0, 0, []) return resLC-79 单词搜索
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
输入:board = [[“A”,“B”,“C”,“E”],[“S”,“F”,“C”,“S”],[“A”,“D”,“E”,“E”]], word = “ABCCED”
输出:true
class Solution: def exist(self, board: List[List[str]], word: str) -> bool: def dfs(i, j, k): if k == len(word) - 1 and 0<=i<=a-1 and 0<=j<=b-1 and word[k] == board[i][j]: return True if not 0<=i<=a-1 or not 0<=j<=b-1 or word[k] != board[i][j]: return False board[i][j] = '' i1 = dfs(i-1, j, k+1) i2 = dfs(i+1, j, k+1) j1 = dfs(i, j-1, k+1) j2 = dfs(i, j+1, k+1) # 这步退格很关键 board[i][j] = word[k] return i1 or i2 or j1 or j2 a, b = len(board), len(board[0]) for i in range(0, a): for j in range(0, b): if dfs(i, j, 0): return True return False LC-47 全排列2
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
示例 1:
输入:nums = [1,1,2]
输出:
[[1,1,2],
[1,2,1],
[2,1,1]]
示例 2:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
回溯,全排列类问题,需要对数组排序
新增used array用来记录index是否被访问的状态。状态回退时,不仅要回退path,used也需要回退
class Solution: def permuteUnique(self, nums: List[int]) -> List[List[int]]: res = [] used = [0] * len(nums) # 排序 nums.sort() if not nums: return [] def dfs(path): if len(path) == len(nums): res.append(path[:]) return for i in range(len(nums)): if used[i] > 0: continue # 同层前一个数相同,且未被用到,则需要跳过 if i > 0 and nums[i] == nums[i-1] and not used[i-1]: continue path.append(nums[i]) used[i] = 1 dfs(path) # 状态回退 path.pop() used[i] = 0 dfs([]) return resLCR 082. 组合总和 II
给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用一次。
注意:解集不能包含重复的组合。
示例 1:
输入: candidates = [10,1,2,7,6,1,5], target = 8,
输出:
[
[1,1,6],
[1,2,5],
[1,7],
[2,6]
]
排列组合题,先排序;因为同个数字只能用一次,数字相同时,取最后一个。
class Solution: def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]: if not candidates: return [] candidates.sort() n = len(candidates) res = [] def backtrack(i, tmp_sum, tmp_list): if tmp_sum == target: res.append(tmp_list) return for j in range(i, n): if tmp_sum + candidates[j] > target : break if j > i and candidates[j] == candidates[j-1]:continue backtrack(j + 1, tmp_sum + candidates[j], tmp_list + [candidates[j]]) backtrack(0, 0, []) return resDFS/BFS
LC-200 岛屿数量
给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [
[“1”,“1”,“1”,“1”,“0”],
[“1”,“1”,“0”,“1”,“0”],
[“1”,“1”,“0”,“0”,“0”],
[“0”,“0”,“0”,“0”,“0”]
]
输出:1
DFS
class Solution: def numIslands(self, grid: List[List[str]]) -> int: rows = len(grid) cols = len(grid[0]) def dfs(grid, i, j): if i >= rows or i < 0 or j >= cols or j < 0 or grid[i][j] == '0': return grid[i][j] = '0' dfs(grid, i, j+1) dfs(grid, i, j-1) dfs(grid, i+1, j) dfs(grid, i-1, j) count = 0 for i in range(rows): for j in range(cols): if grid[i][j] == '1': dfs(grid, i, j) count += 1 return countBFS 借助队列
class Solution: def numIslands(self, grid: List[List[str]]) -> int: #bfs from collections import deque def bfs(grid, i, j): queue = deque([[i, j]]) while queue: l = queue.popleft() x, y = l[0], l[1] if 0 <= x < len(grid) and 0 <= y < len(grid[0]) and grid[x][y] == '1': grid[x][y] = '0' queue.extend([[x+1, y], [x-1, y], [x, y+1], [x, y-1]]) count = 0 for i in range(len(grid)): for j in range(len(grid[0])): if grid[i][j] == '1': bfs(grid, i, j) count += 1 return countLC-695 岛屿的最大面积
给定一个包含了一些 0 和 1 的非空二维数组 grid 。
一个 岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在水平或者竖直方向上相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
找到给定的二维数组中最大的岛屿面积。(如果没有岛屿,则返回面积为 0)
示例 1:
[[0,0,1,0,0,0,0,1,0,0,0,0,0],
[0,0,0,0,0,0,0,1,1,1,0,0,0],
[0,1,1,0,1,0,0,0,0,0,0,0,0],
[0,1,0,0,1,1,0,0,1,0,1,0,0],
[0,1,0,0,1,1,0,0,1,1,1,0,0],
[0,0,0,0,0,0,0,0,0,0,1,0,0],
[0,0,0,0,0,0,0,1,1,1,0,0,0],
[0,0,0,0,0,0,0,1,1,0,0,0,0]]
对于上面这个给定矩阵应返回 6。注意答案不应该是 11 ,因为岛屿只能包含水平或垂直的四个方向的 1 。
BFS, 增加面积的计数
class Solution: def maxAreaOfIsland(self, grid: List[List[int]]) -> int: from collections import deque def bfs(grid, i, j): queue = deque([[i, j]]) area = 0 while queue: l = queue.popleft() x, y = l[0], l[1] if 0<=x<len(grid) and 0<=y<len(grid[0]) and grid[x][y] == 1: grid[x][y] = 0 area += 1 queue.extend([[x-1, y], [x+1, y], [x, y-1], [x, y+1]]) return area max_area = 0 for i in range(len(grid)): for j in range(len(grid[0])): if grid[i][j] == 1: max_area = max(bfs(grid, i, j), max_area) return max_areaclass Solution(object): def maxAreaOfIsland(self, grid): """ :type grid: List[List[int]] :rtype: int """ row = len(grid) col = len(grid[0]) res = 0 def dfs(i, j): if i >= 0 and i <= row - 1 and j >= 0 and j <= col - 1 and grid[i][j]: grid[i][j] = 0 return 1 + dfs(i-1, j) + dfs(i+1, j) + dfs(i, j-1) + dfs(i, j+1) return 0 for i in range(row): for j in range(col): if grid[i][j]: res = max(res, dfs(i, j)) return resLC-1254 统计封闭岛屿的数目
有一个二维矩阵 grid ,每个位置要么是陆地(记号为 0 )要么是水域(记号为 1 )。
我们从一块陆地出发,每次可以往上下左右 4 个方向相邻区域走,能走到的所有陆地区域,我们将其称为一座「岛屿」。
如果一座岛屿 完全 由水域包围,即陆地边缘上下左右所有相邻区域都是水域,那么我们将其称为 「封闭岛屿」。
请返回封闭岛屿的数目。
输入:grid = [[1,1,1,1,1,1,1,0],[1,0,0,0,0,1,1,0],[1,0,1,0,1,1,1,0],[1,0,0,0,0,1,0,1],[1,1,1,1,1,1,1,0]]
输出:2
解释:
灰色区域的岛屿是封闭岛屿,因为这座岛屿完全被水域包围(即被 1 区域包围)。
思路:先把边界全部都置为1,再进行整体的dfs,dfs中遇到1就返回
class Solution: def closedIsland(self, grid: List[List[int]]) -> int: m, n = len(grid), len(grid[0]) def dfs(x, y): if grid[x][y] == 1: return grid[x][y] = 1 for mx, my in [(x-1, y), (x+1, y), (x, y-1), (x, y+1)]: if 0 <= mx < m and 0 <= my < n: dfs(mx, my) for i in range(m): dfs(i, 0) dfs(i, n-1) for j in range(n): dfs(0, j) dfs(m-1, j) ans = 0 for i in range(m): for j in range(n): if grid[i][j] == 0: dfs(i, j) ans += 1 return ansLC-394 字符串解码
给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4]的输入。
示例 1:
输入:s = “3[a]2[bc]”
输出:“aaabcbc”
示例 2:
输入:s = “3[a2[c]]”
输出:“accaccacc”
class Solution: def decodeString(self, s: str) -> str: stack, res, multi = [], "", 0 for c in s: print(res) if c == '[': # 遇到 [ 暂存结果和数字 stack.append([multi, res]) res, multi = "", 0 elif c == ']': # 遇到 ] pop 组装 cur_multi, last_res = stack.pop() res = last_res + cur_multi * res elif '0' <= c <= '9': multi = multi * 10 + int(c) else: res += c return resLC-207 课程表
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
例如,先修课程对 [0, 1] 表示:想要学习课程 0 ,你需要先完成课程 1 。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
输入:numCourses = 2, prerequisites = [[1,0]]
输出:true
解释:总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。
拓扑排序BFS步骤(最开始的先入队列)
- 新建入度表,没有入度说明没有先修要求;新建邻接矩阵,表示 先修 -> 后修
- 入度为 0 的 index 入队列
- 出队列,总数 -1,对应后修课程入度 -1,判断是否为0,为0继续入队。
- 最终判断是否将所有课程遍历结束
class Solution: def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool: indegrees = [0] * numCourses adjacency = [[] for _ in range(numCourses)] queue = deque() for cur, pre in prerequisites: indegrees[cur] += 1 # 学完之后可学的课程 adjacency[pre].append(cur) # 放入没有入度的节点 for i in range(len(indegrees)): if not indegrees[i]: queue.append(i) while queue: pre = queue.popleft() numCourses -= 1 for cur in adjacency[pre]: indegrees[cur] -= 1 if not indegrees[cur]: queue.append(cur) return not numCoursesDFS:
class Solution: def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool: def dfs(i, adjacency, flags): if flags[i] == -1: return True if flags[i] == 1: return False flags[i] = 1 for j in adjacency[i]: if not dfs(j, adjacency, flags): return False flags[i] = -1 return True adjacency = [[] for _ in range(numCourses)] flags = [0 for _ in range(numCourses)] for cur, pre in prerequisites: adjacency[pre].append(cur) for i in range(numCourses): if not dfs(i, adjacency, flags): return False return TrueLC-71 简化路径
给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 ‘/’ 开头),请你将其转化为 更加简洁的规范路径。
输入:path = “/home//foo/”,输出:“/home/foo”
输入:path = “/home/user/Documents/…/Pictures”,输出:“/home/user/Pictures”
输入:path = “/…/a/…/b/c/…/d/./”,输出:“/…/b/d”
输入:path = “/…/”,输出:“/”
使用栈
class Solution: def simplifyPath(self, path: str) -> str: names = path.split("/") stack = list() for name in names: if name == "..": if stack: stack.pop() elif name and name != ".": stack.append(name) return "/" + "/".join(stack)LC-547 省份数量
有 n 个城市,其中一些彼此相连,另一些没有相连。如果城市 a 与城市 b 直接相连,且城市 b 与城市 c 直接相连,那么城市 a 与城市 c 间接相连。
省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个 n x n 的矩阵 isConnected ,其中 isConnected[i][j] = 1 表示第 i 个城市和第 j 个城市直接相连,而 isConnected[i][j] = 0 表示二者不直接相连。
返回矩阵中 省份 的数量。
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution: def buildTree(self, inorder: List[int], postorder: List[int]) -> TreeNode: if len(inorder) == 0: return None root = TreeNode(postorder[-1]) mid = inorder.index(postorder[-1]) # left root.left = self.buildTree(inorder[:mid], postorder[:mid]) # right root.right = self.buildTree(inorder[mid+1:], postorder[mid:-1]) return rootclass UnionFind: def __init__(self): self.father = {} # 额外记录集合的数量 self.num_of_sets = 0 def find(self,x): root = x while self.father[root] != None: root = self.father[root] while x != root: original_father = self.father[x] self.father[x] = root x = original_father return root def merge(self,x,y): root_x,root_y = self.find(x),self.find(y) if root_x != root_y: self.father[root_x] = root_y # 集合的数量-1 self.num_of_sets -= 1 def add(self,x): if x not in self.father: self.father[x] = None # 集合的数量+1 self.num_of_sets += 1class Solution: def findCircleNum(self, M: List[List[int]]) -> int: uf = UnionFind() for i in range(len(M)): uf.add(i) for j in range(i): if M[i][j]: uf.merge(i,j) return uf.num_of_setsLC-17 电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
输入:digits = “23”
输出:[“ad”,“ae”,“af”,“bd”,“be”,“bf”,“cd”,“ce”,“cf”]
class Solution: def letterCombinations(self, digits: str) -> List[str]: if len(digits) < 1: return [] size = len(digits) res = [] dic = {"2": ['a', 'b', 'c'], "3": ['d', 'e', 'f'], '4': ['g', 'h', 'i'], '5': ['j', 'k', 'l'], '6': ['m', 'n', 'o'], '7': ['p', 'q', 'r', 's'], '8': ['t', 'u', 'v'], '9': ['w', 'x', 'y', 'z'] } def dfs(index, path): if len(path) == size: res.append(''.join(path)) else: dig = digits[index] for item in dic[dig]: dfs(index + 1, path + [item]) dfs(0, []) return res字符串
LC-151 翻转字符串里的单词
给你一个字符串 s ,逐个翻转字符串中的所有 单词 。
单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
请你返回一个翻转 s 中单词顺序并用单个空格相连的字符串。
说明:
输入字符串 s 可以在前面、后面或者单词间包含多余的空格。
翻转后单词间应当仅用一个空格分隔。
翻转后的字符串中不应包含额外的空格。
输入:s = " hello world "
输出:“world hello”
解释:输入字符串可以在前面或者后面包含多余的空格,但是翻转后的字符不能包括。
class Solution: def reverseWords(self, s: str) -> str: tmp = [] res = [] for word in s.strip().split(' '): if len(word.strip()) >= 1: tmp.append(word.strip()) for i in range(len(tmp)): res.append(tmp[len(tmp) - i - 1]) return ' '.join(res)直接写就好了
LC-165 比较版本号
给你两个版本号 version1 和 version2 ,请你比较它们。
版本号由一个或多个修订号组成,各修订号由一个 ‘.’ 连接。每个修订号由 多位数字 组成,可能包含 前导零 。每个版本号至少包含一个字符。修订号从左到右编号,下标从 0 开始,最左边的修订号下标为 0 ,下一个修订号下标为 1 ,以此类推。例如,2.5.33 和 0.1 都是有效的版本号。
比较版本号时,请按从左到右的顺序依次它们的修订号。比较修订号时,只需比较 忽略任何前导零后的整数值 。也就是说,修订号 1 和修订号 001 相等 。如果版本号没有指定某个下标处的修订号,则该修订号视为 0 。例如,版本 1.0 小于版本 1.1 ,因为它们下标为 0 的修订号相同,而下标为 1 的修订号分别为 0 和 1 ,0 < 1 。
返回规则如下:
如果 version1 > version2 返回 1,
如果 version1 < version2 返回 -1,
除此之外返回 0。
转int后,pop掉末尾的0
class Solution: def compareVersion(self, version1: str, version2: str) -> int: v1 = [int(item) for item in version1.split('.')] v2 = [int(item) for item in version2.split('.')] # 弹出0 while len(v1) > 1 and v1[-1] == 0: v1.pop() while len(v2) > 1 and v2[-1] == 0: v2.pop() index = 0 while index < min(len(v1), len(v2)): if v1[index] > v2[index]: return 1 elif v1[index] < v2[index]: return -1 else: index += 1 if len(v1) > len(v2): return 1 elif len(v1) < len(v2): return -1 else: return 0LC-93 复原ip地址
给定一个只包含数字的字符串,用以表示一个 IP 地址,返回所有可能从 s 获得的 有效 IP 地址 。你可以按任何顺序返回答案。
有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 ‘.’ 分隔。
例如:“0.1.2.201” 和 “192.168.1.1” 是 有效 IP 地址,但是 “0.011.255.245”、“192.168.1.312” 和 “192.168@1.1” 是 无效 IP 地址。
示例 1:
输入:s = “25525511135”
输出:[“255.255.11.135”,“255.255.111.35”]
class Solution: def restoreIpAddresses(self, s: str) -> List[str]: if len(s) < 4 or len(s)> 12: return [] res = [] def dfs(remain, path): if len(path) == 4 and not remain: res.append('.'.join(path)) return for i in range(0, min(3, len(remain)), 1): ans = remain[0:i+1] # 大于255 和 先导有0要排除 if int(ans) > 255 or len(str(int(ans))) != len(ans): continue dfs(remain[i+1:], path + [ans]) dfs(s, []) return resLC-227 基本计算器2
给你一个字符串表达式 s ,请你实现一个基本计算器来计算并返回它的值。整数除法仅保留整数部分。
示例 1:
输入:s = “3+2*2”
输出:7
class Solution: def calculate(self, s: str) -> int: n = len(s) stack = [] preSign = '+' num = 0 for i in range(n): if s[i] != ' ' and s[i].isdigit(): num = num * 10 + int(s[i]) if i == n - 1 or s[i] in '+-*/': if preSign == '+': stack.append(num) elif preSign == '-': stack.append(-num) elif preSign == '*': stack.append(stack.pop() * num) else: stack.append(int(stack.pop() / num)) preSign = s[i] num = 0 return sum(stack)LC-443 压缩字符串
给你一个字符数组 chars ,请使用下述算法压缩:
从一个空字符串 s 开始。对于 chars 中的每组 连续重复字符 :
如果这一组长度为 1 ,则将字符追加到 s 中。否则,需要向 s 追加字符,后跟这一组的长度。
示例 1:
输入:chars = [“a”,“a”,“b”,“b”,“c”,“c”,“c”]
输出:返回 6 ,输入数组的前 6 个字符应该是:[“a”,“2”,“b”,“2”,“c”,“3”]
解释:
“aa” 被 “a2” 替代。“bb” 被 “b2” 替代。“ccc” 被 “c3” 替代。
class Solution: def compress(self, chars: List[str]) -> int: ret = 0 head = tail = 0 n = len(chars) while tail < n: cnt = 0 # 尾指针向后 while tail < n and chars[tail] == chars[head]: tail += 1 cnt += 1 chars[ret] = chars[head] # 填写字母 ret += 1 if cnt > 1: # 填写数字 for i in range(len(str(cnt))): chars[ret] = list(str(cnt))[i] ret += 1 head = tail return ret LC-145 LRU缓存机制
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制 。
实现 LRUCache 类:
双向链表,哈希表。
其中双向链表可以更好的定位到前后的元素,而哈希表是记录所有 key 所在的位置
- get 操作:如果哈希表中有这个 key,则返回这个 key 的值,并且由于是最近使用的,所以需要将其移动至双向链表的头部;没有则返回-1
- put 操作:将(key,value)的一个 pair 加入到双向链表中,这边就存在 2 种情况:如果有则直接修改值,并且移动至链表头部;如果没有值,则新建链表节点,移动至头部,并且需要检查总的长度是否超过 LRU 总的容量,超过则要删除链表中最后一个节点,并且在哈希表里也要弹出这个节点对应的 key。
class DLinkedNode: def __init__(self, key=0, value=0): self.key = key self.value = value self.prev = None self.next = Noneclass LRUCache: def __init__(self, capacity: int): self.cache = {} self.capacity = capacity self.size = 0 self.head = DLinkedNode() self.tail = DLinkedNode() self.head.next = self.tail self.tail.prev = self.head def addToHead(self, node): node.next = self.head.next node.prev = self.head self.head.next = node node.next.prev = node def removeNode(self, node): node.prev.next = node.next node.next.prev = node.prev def moveToHead(self, node): self.removeNode(node) self.addToHead(node) def removeTail(self): node = self.tail.prev self.removeNode(node) return node def get(self, key: int) -> int: if key not in self.cache: return -1 # 如果 key 存在,先通过哈希表定位,再移到头部 node = self.cache[key] self.moveToHead(node) return node.value def put(self, key: int, value: int) -> None: if key in self.cache: node = self.cache[key] node.value = value # move to the header self.moveToHead(node) else: node = DLinkedNode(key, value) self.cache[key] = node # move to the header self.addToHead(node) self.size += 1 if self.size > self.capacity: # remove the tail removed = self.removeTail() self.cache.pop(removed.key) self.size -= 1LC-54 螺旋矩阵
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。
class Solution: def spiralOrder(self, matrix: List[List[int]]) -> List[int]: left = top = 0 right = len(matrix[0]) bottom = len(matrix) ret = [] while left < right and top < bottom: for i in range(left, right): ret.append(matrix[top][i]) top += 1 for i in range(top, bottom): ret.append(matrix[i][right - 1]) right -= 1 if left < right and top < bottom: for i in range(right - 1, left - 1, -1): ret.append(matrix[bottom - 1][i]) bottom -= 1 for i in range(bottom - 1, top - 1, -1): ret.append(matrix[i][left]) left += 1 return retLC-215 数组中的第K个最大元素
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
示例 1:
输入: [3,2,1,5,6,4] 和 k = 2
输出: 5
直接用python heapq包处理
class Solution: def findKthLargest(self, nums: List[int], k: int) -> int: # 直接调用 python 包 maxHeap = [] for x in nums: heapq.heappush(maxHeap, -x) for _ in range(1, k, 1): heapq.heappop(maxHeap) print(maxHeap) return -maxHeap[0]class Solution: def findKthLargest(self, nums: List[int], k: int) -> int: heapsize = len(nums) def heapify(nums, index, heapsize): max = index left = 2 * index + 1 right = 2 * index + 2 if left < heapsize and nums[left] > nums[max]: max = left if right < heapsize and nums[right] > nums[max]: max = right if max != index: swap(nums, index, max) # 递归代入新的max节点 heapify(nums, max, heapsize) def swap(nums, i, j): tmp = nums[i] nums[i] = nums[j] nums[j] = tmp def buildHeap(nums, heapsize): for i in range(heapsize // 2 - 1, -1, -1): # 只需要调整有子节点的父节点 heapify(nums, i, heapsize) buildHeap(nums, heapsize) for i in range(k-1): swap(nums, 0, heapsize-1) heapsize -= 1 heapify(nums, 0, heapsize) return nums[0]快排:
def quick_sort(nums): if len(nums) <= 1: return nums key = nums.pop() left = [] right = [] for x in nums: if x < key: left.append(x) else: right.append(x) return quick_sort(left) + [key] + quick_sort(right)原地快排:
https://zhuanlan.zhihu.com/p/63227573
def quick_sort(lists,i,j): if i >= j: return list pivot = lists[i] low = i high = j while i < j: while i < j and lists[j] >= pivot: j -= 1 lists[i]=lists[j] while i < j and lists[i] <=pivot: i += 1 lists[j]=lists[i] lists[j] = pivot quick_sort(lists,low,i-1) quick_sort(lists,i+1,high) return lists归并:
#将两个数组从大到小合并def merge(left, right): i = 0 j = 0 res = [] while i < len(left) and j < len(right): if left[i] < right[j]: res.append(left[i]) i += 1 else: res.append(right[j]) j += 1 res += left[i:] res += right[j:] return resdef merge_sort(nums): n = len(nums) if n <= 1: return nums mid = n//2 left = merge_sort(nums[:mid]) right = merge_sort(nums[mid:]) return merge(left, right) 插入排序:
#从索引1元素a开始,依次和前面比较(从后往前),当该元素a小于已经排序好元素b,那么b向后移一位.最后肯定留一个"坑",把a塞进去.def insertions_sort(nums): for i in range(1,len(nums)): temp = nums[i] j = i-1 while j >= 0 and nums[j] > temp: nums[j+1] = nums[j] j -= 1 nums[j+1] = temp return nums选择排序:
#遍历数组,每次都把最小的放到相应位置def select_sort(nums): n = len(nums) for i in range(n-1): for j in range(i,n-1): if nums[i] > nums[j]: nums[i],nums[j] = nums[j],nums[i] return nums冒泡排序:
#一句话,让大的数沉底#两两比较,让大的数放在数组末端def bubbleSort(nums): n = len(nums) f = n for _ in range(n-1): for i in range(f-1): if nums[i] > nums[i+1]: nums[i],nums[i+1] = nums[i+1],nums[i] f -= 1 return nums